
Leveling the Playing Field: Livecodebench’s Big Bug Fix
Three major fixes that reshaped competitive coding scores and why your numbers may look very different now




tl;dr: the official LiveCodeBench has serious bugs that can impact results by 50% or more. We pushed PRs to patch the bugs [1], [2].
When OpenAI released the gpt-oss last week, the official blog reports the model’s performance on AIME but there is no official report of how good the model is for coding. Out of curiosity, we plugged the model into our post-training workflow and reported a LiveCodeBench score of 0.70 for pass@1 in this blog post.
Our blog post on benchmarking gpt-oss-20b attracted post-training researchers interested in reproducing our results. This blog post discusses our internal LiveCodeBench setup and our PRs to the official repo that include three major bug fixes.
Quick Background: What is LiveCodeBench?
LiveCodeBench is a continuously-updated and contamination-aware benchmark maintained by researchers at UC Berkeley, MIT, and Cornell. Problems are scraped shortly after they appear in live contests, so teams can evaluate against tasks that were indisputably unseen at model-training time.
All problems are diverse competitive programming questions. The benchmark uses execution-based accuracy (all hidden tests pass) as the metric and averages across the number of samples generated for each problem.
How We Found the Bug
We first suspected something was off when we tried to reproduce Qwen3-8b (instruct) official Livecodebench results. Instead of matching their reported numbers, we consistently saw that the technical report was about 50% higher than the new one. (eg: 57.8 vs 38.3 for Qwen3-8b). Digging deeper, we inspected the raw outputs and spotted a strange pattern: every response was getting cut off right after the ### token. For many problems, Qwen3’s actual solution began after a header like ### Solution Code. Upon closer inspection, we found that the official Livecodebench evaluation treated that marker as an end-of-sequence token and completely discarded the real answer.
Looking at the data, we also noticed that some responses had no code, although the answer was enclosed within backticks ``` This led us to the second bug: the official LCB was just checking for enclosing backticks without confirming there was actual code within those. Sometimes there was just a comment, and the LCB script would just extract the comment while ignoring the actual code generated by the model.
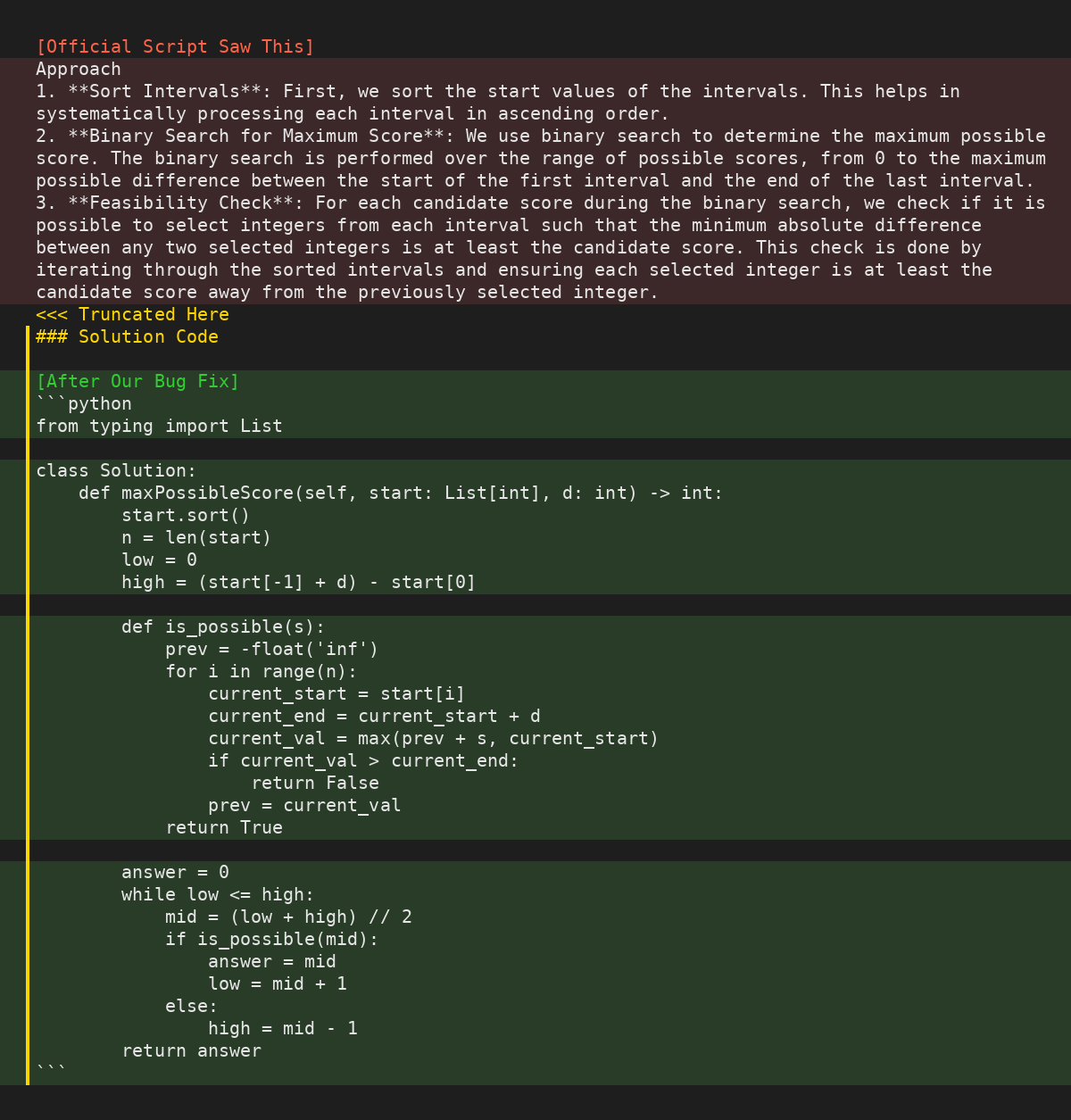
We also noticed that the official LCB repo hard-codes the chat templates instead of using the chat completions API. This is another source for errors in the evaluation pipeline.
The Three Main Fixes
Fix 1: Disable the problematic “—stop” flag that causes premature cutoff
The most prominent issue is that LCB has a default stop token that automatically cuts off everything after a specific phrase, sometimes including the actual code response. Specifically, they have the following code:
parser.add_argument(
"--stop",
default="###",
type=str,
help="Stop token (use `,` to separate multiple tokens)",
)This logic is problematic because some models have the tendency to use markdown syntax in their response, generating code only after a ### solution code header. As a result, the whole code block is discarded and the response is marked as wrong.
To remedy this, we change the stop token to None, so that the model only stops properly when it either outputs the <eos> token or hits the max token limit.
Fix 2: Add the check for python tags when extracting code from backticks
Another issue is that LCB checks for the last pair of backticks (ie, ```...```) to extract the code implementation. This has the risk of extracting non-code blocks if the model decides to put other content in backticks for readability or stylistic reasons. As a result, sometimes we observe that LCB extracts the model’s explanations and summaries as code outputs and grade them as false.
The most effective fix is to prioritize checking for the last pair of backticks with a python tag (ie, ```python…```). This filters out non-python code blocks while still playing fair to demand the model to wrap the code in backticks.
Fix 3: Deprecate hard-coded chat templates
The above two issues unfairly grade the model, but this issue directly breaks it: the incorrect application of custom chat templates. Models are sensitive to their training chat template and the specific system prompt used, so altering the template config can cause catastrophic degrade in their performance. Unfortunately, LCB manually writes the template for each model in a single file and applies the template to the model prompt through formatted strings at runtime. For example, this is the manual template for Qwen3 models:
SYSTEM_MESSAGE_CODEQWEN = (
f"<|im_start|>system\nYou are a helpful assistant <|im_end|>\n<|im_start|>user"
)The fix is simple: we move away from hard-coded templates and use the mature chat endpoints that is almost universally present in all LLM inference clients. Examples include OpenAI’s client.chat.completion endpoint and vLLM’s llm.chat endpoint. These chat endpoints, different from the traditional completion endpoints which LCB uses, automatically apply the correct chat template that is specified by the model’s config file on HuggingFace. Therefore, they eliminate any possible misalignment between a model and its chat template.
Before vs. After: The Numbers
We are able to better replicate official reports from foundation model providers after our bug fixes.
Reproduction of public benchmarks using our internal LCB setup:
Technical report: 0.575
Internal result: 0.578
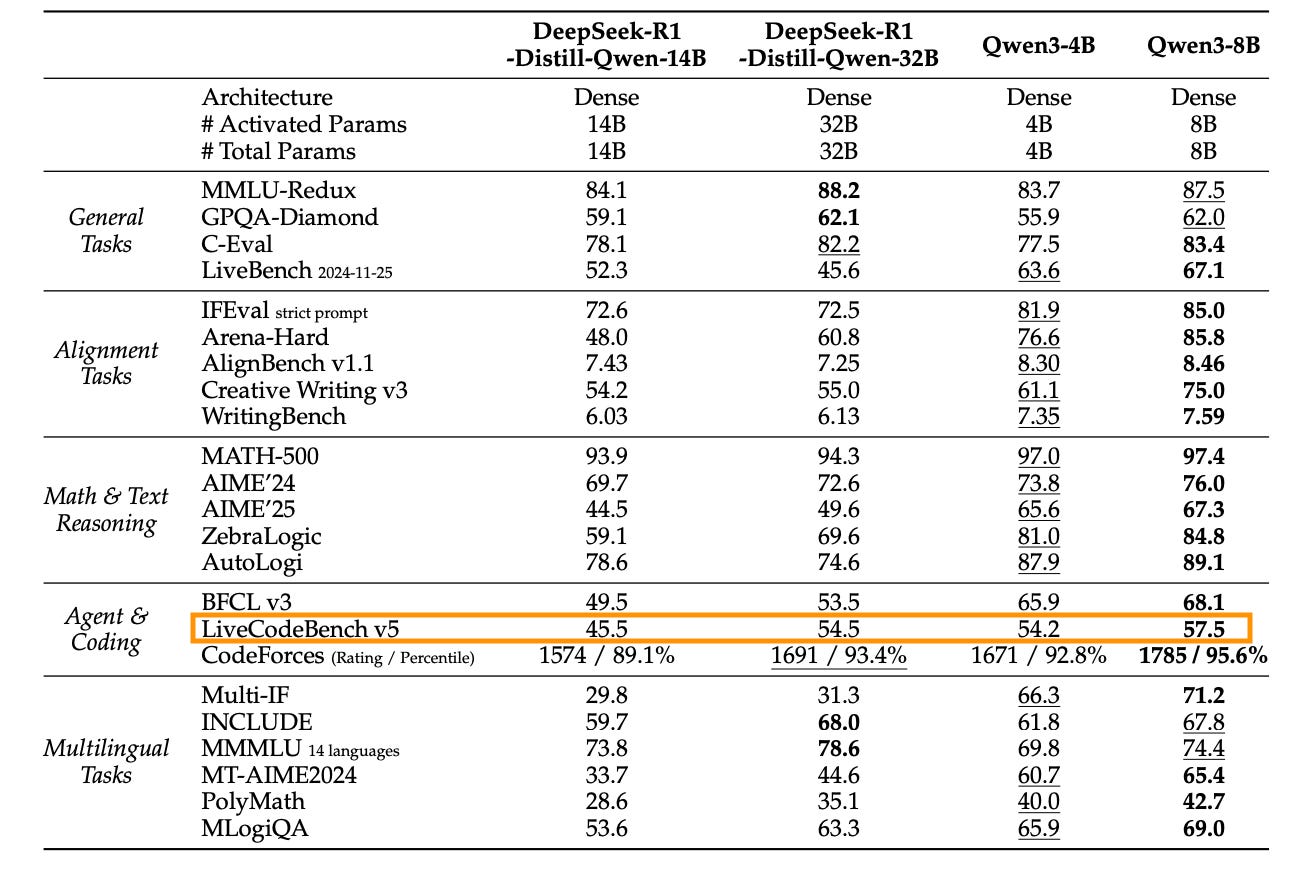
Open Thoughts paper: 36.2
Internal result: 35.5
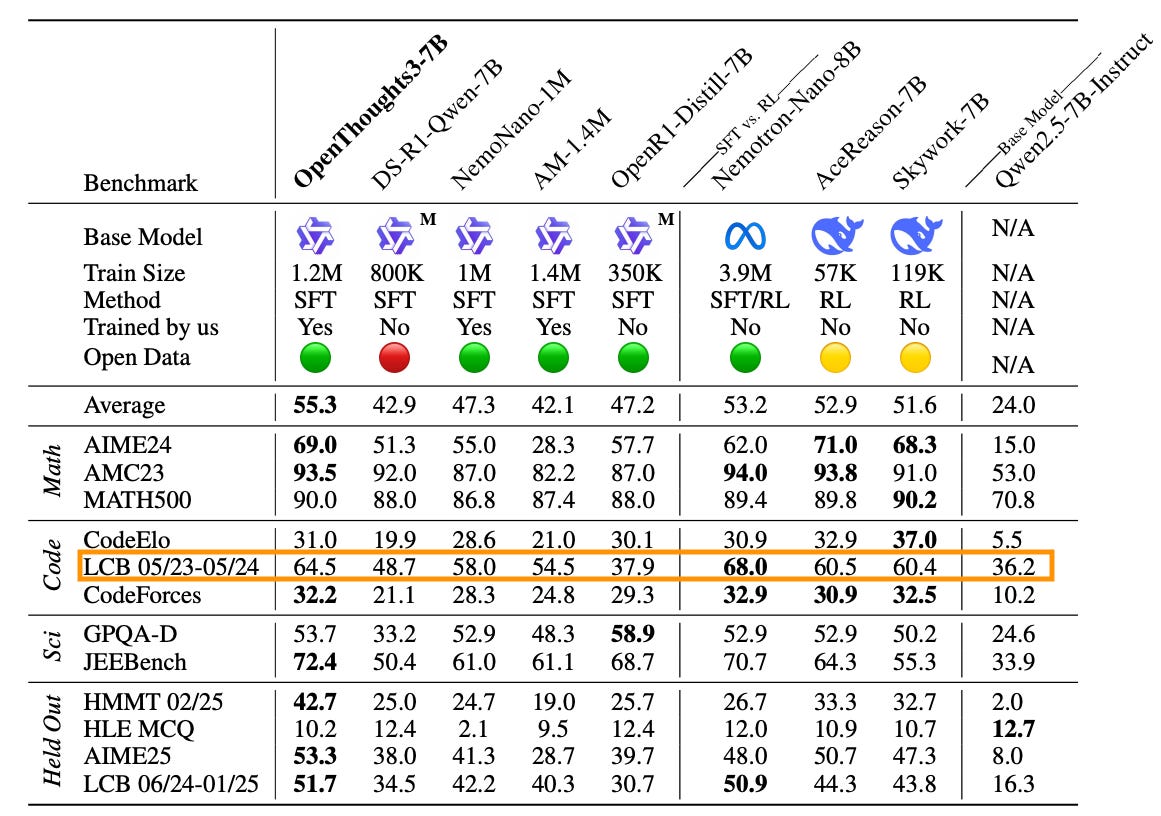
Open Thoughts paper: 64.5
Internal result: 70
Why this matters
As the AI landscape evolves rapidly, official benchmarks are one of the most critical infrastructures that practitioners rely on for deciding what models are best suited for their use cases. That is why it is important that the benchmarks are reliable and the scores reproducible. Our bug patches to LiveCodeBench are in support of open science and enabling the community to replicate scores in the official technical reports.
References:
LiveCodeBench: https://livecodebench.github.io/
PR to fix stop flag: https://github.com/LiveCodeBench/LiveCodeBench/pull/117
PR to fix the backticks: https://github.com/LiveCodeBench/LiveCodeBench/pull/118