
Gaming the System: Goodhart’s Law Exemplified in AI Leaderboard Controversy
How the race to the top in AI benchmarks is leading to specialized optimization at the expense of real-world performance




The recent uproar over the LMSYS (now LMArena) Chatbot Arena leaderboard is a striking, real-world example of Goodhart’s Law in action. Goodhart’s Law – originally from economics – warns that “when a measure becomes a target, it ceases to be a good measure”.
In AI model evaluation, this means that once researchers and companies focus on beating a particular benchmark, the benchmark itself can become misleading.

The Chatbot Arena controversy has proved this in practice: model developers have found ways to optimize for high Arena scores (the target), ultimately distorting the Arena’s ability to measure true model quality.
LMSYS and Its Popularity
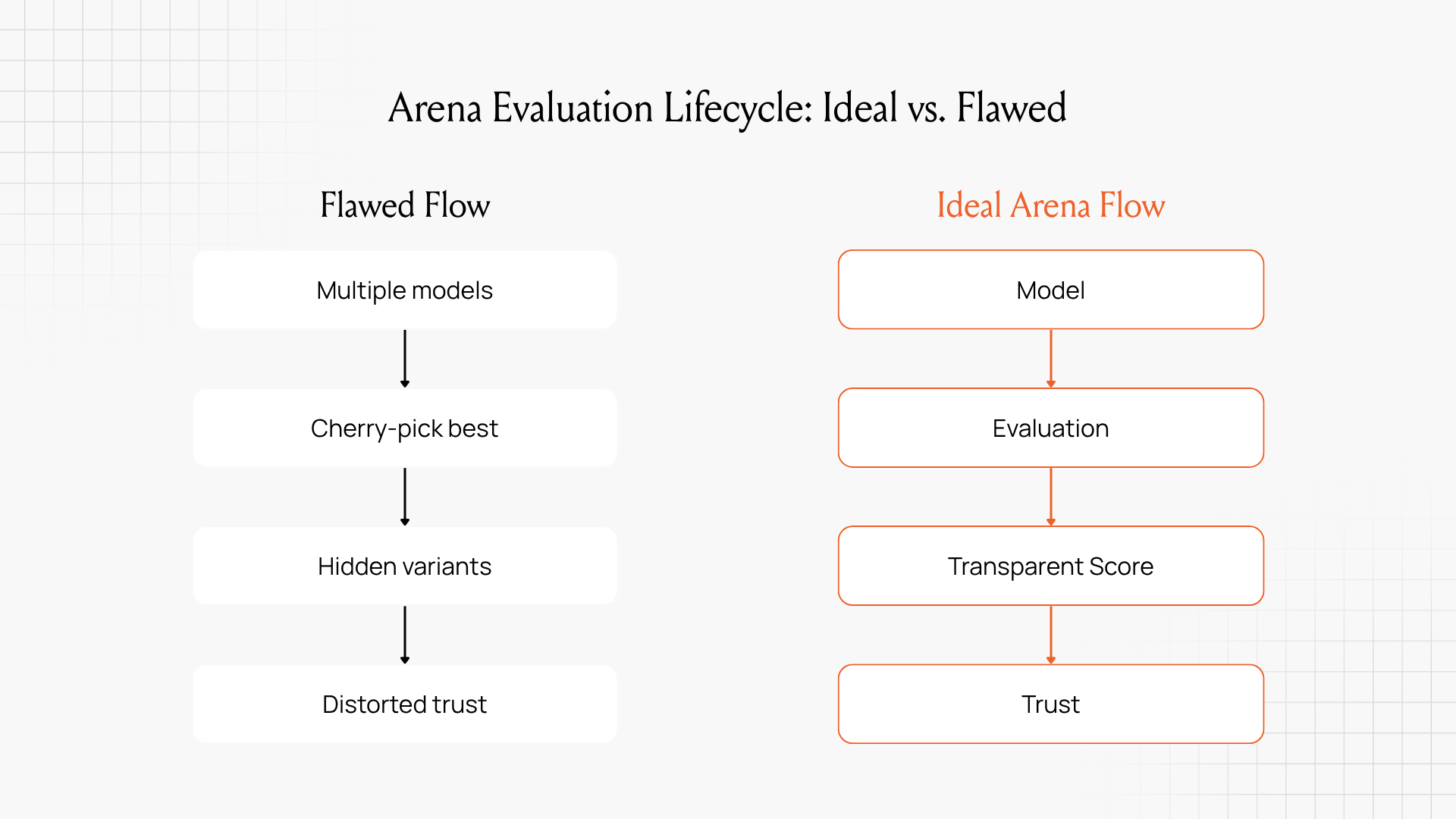
LMSYS (now LMArena) is a crowdsourced evaluation platform for chat-based AI models. Launched in 2023 as a research project at UC Berkeley, it quickly became the de facto leaderboard for judging “frontier” LLMs. The system works by pitting two anonymous models in a side-by-side “battle”: a user submits a prompt, each model gives an answer, and the user votes for the better response. Over time, these votes are aggregated into Elo-style ratings, yielding a ranked leaderboard of “the best” models.
Because of its community-driven format and the excitement around new AI systems, the Arena gained immense influence. As one analyst noted, the Arena has “become one of the most influential leaderboards in the LLM world, which means that billions of dollars of investment are now being evaluated based on those scores”.
Model developers – from big labs to startups – raced to test their latest models. Unreleased or pre-release models often appeared under pseudonyms, letting companies gauge performance before public launch. Many industry insiders came to treat the Arena ranking as a key proxy for “who’s winning” in the AI race.
The Gaming of the Leaderboard

Enter the new paper “The Leaderboard Illusion” by Singh et al. (2025), with authors from Cohere, Stanford, MIT, Allen Institute for AI, and others. This 68-page analysis reports systematic distortions in the Arena “playing field.” The authors found that:
“Undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired.”
They show that such practices have led to “biased Arena scores due to selective disclosure of performance results,” and cite “27 private LLM variants tested by Meta in the lead-up to the Llama-4 release”.

In short, large companies like Meta, OpenAI, Google and Amazon were able to privately pit many model versions in the Arena and then only publish the best results – a classic Goodhart move.

These tactics effectively turn the Arena leaderboard into a target to optimize, instead of a neutral measure. As the authors note, giving a few players the chance to cherry-pick models and hide failures creates a “distorted playing field”. They estimate that even a modest increase in access to Arena data could boost a model’s Arena performance by up to 112%.
These findings align precisely with Goodhart’s Law: once model labs began treating Arena ranking as the target metric, the metrics lost validity. By selectively showcasing only their strongest variants (Goodhart’s “best-case” models), labs inflated their scores.
Reactions from the AI Community
Unsurprisingly, the Chatbot Arena revelations provoked strong commentary across the AI community. Sara Hooker (Cohere’s VP of AI Research and a co-author of the study) emphasized that scientific integrity is at stake. On X she wrote:
“It is critical for scientific integrity that we trust our measure of progress. The Chatbot Arena has become the go-to evaluation for frontier AI systems… We show that coordination among a handful of providers and preferential policies… have led to distorted Arena rankings.”
She urged that “all model evaluation results – including private variants – should be permanently published…with no option to retract or selectively hide scores,” and that uniform limits on private testing are needed. Hooker’s point echoes Collinear AI’s CEO, Nazneen Rajani’s framing: benchmarks must be transparent to be trustworthy.
On X, former OpenAI Director Andrej Karpathy noted that the Arena had “so much focus (partly my fault?)” that labs were overfitting to it. Karpathy proposed an alternative evaluation: the OpenRouter AI rankings (based on real API usage and costs). He wrote that OpenRouter’s model popularity reflects real-world user preferences and is “very difficult to game”.
Some tech leaders pushed back on the paper’s implications. In interviews and responses, LMArena co-founder Ion Stoica (UC Berkeley professor) defended the platform. He called the study’s claims “full of inaccuracies” and “questionable”. LMArena tweeted that “inviting model providers to submit more tests… does not mean the second model provider is treated unfairly”, arguing that any lab can simply submit more models to catch up. Similarly, Google DeepMind researcher Armand Joulin disputed the findings on X, asserting that Google “only sent one AI model variant for pre-release testing,” contrary to the implication of multiple hidden tests. These defenders urged caution, but their rebuttals did not dispute the raw data analysis.
LMArena also offered an official response on X after the paper went public. In it, the Arena thanked the authors but noted what it called “factual errors and misleading statements” in the report. The tweet reinforced that their policy allows anyone to submit any number of tests, and if one lab submits more, it’s their choice.
Overall, the community reaction has been mixed but intense. Many AI researchers — from Stanford, MIT, and elsewhere — have highlighted that this incident shows the vulnerabilities of crowdsourced leaderboards. Cohere (one of the study’s co-authors) has taken the lead in calling for change, and some conferences have begun discussions of how to make evaluations more robust and transparent.
Implications for Evaluation Metrics
The LMArena episode is a cautionary tale for AI benchmarking. When a popular metric like an Arena leaderboard is elevated to “target” status, Goodhart’s Law predicts distortions. This is not unique to the Arena – similar issues have arisen when researchers over-optimize for BLEU scores in machine translation or high accuracy on benchmark datasets. BLEU scores measure how closely a machine translation matches human reference translations by counting word overlaps, with higher scores (0-1) indicating better performance.
The clear implication is that no single evaluation metric should be trusted in isolation.

Going forward, the community is discussing several remedies:
Transparency and open results. As Hooker and the paper recommend, all evaluation runs (including rejected or unreported ones) should be recorded and published. This prevents cherry-picking best-case outcomes. In practical terms, the Arena organizers could require that every model variant’s full score trajectory be visible to users, not just a final “top score.”
Uniform testing policies. The paper suggests capping private pre-launch testing uniformly for all providers, and avoiding undisclosed “preview” programs that only some companies know about.
Diverse evaluation signals. AI developers should use multiple benchmarks, including real-world tasks, to avoid overfitting to any one metric. For example, Nazneen notes that we need “stress testing and feedback loops grounded in real-world usage,” not just isolated scores. Platforms like OpenRouter, multi-metric leaderboards, and human-in-the-loop evaluations may complement crowdsourced arenas.
Community and adversarial review. The controversy itself is a sign that independent audits (like the Leaderboard Illusion paper) and public scrutiny are valuable. Encouraging outside researchers to probe and stress-test leaderboards can reveal failures of integrity before they become entrenched.
The LMArena saga is a high-profile case of Goodhart’s Law in modern AI. It reminds researchers and industry that incentives matter and that metrics must be treated carefully. AI is moving toward evaluation frameworks that recognize Goodhart’s pitfall: multi-faceted metrics, periodic blind testing, and mechanisms to detect “score hacking”. When everyone chases the same leaderboard, the leaderboard can become an unreliable guide. Going forward, the AI community must treat any single benchmark with skepticism and invest in more robust, multi-dimensional evaluation strategies.
As Nazneen Rajani emphasizes, upholding scientific integrity requires that “every company building AI needs a robust safety policy—one that embraces employees (and independent researchers) who point out flaws, not silences them”.
Ready to move beyond benchmarks?
See how Collinear enables enterprises to build an AI improvement data flywheel.