
Whose Taste?
More data won't fix the AI verification problem. Different taste might.

The man who passed every check
Kim Philby, standing in his mother’s flat in Drayton Gardens, London, before an array of reporters, was guilty. He had been guilty since 1934, when a Soviet agent named Otto recruited him in Regent’s Park. He was guilty when he joined MI6 in 1940, and when the King awarded him an OBE in 1945 for his wartime intelligence work. And he was guilty in 1955, when the Foreign Secretary stood up in the House of Commons and cleared his name.

It was not until he had been posted to MI6 station in Beirut, when confronted by his old MI6 friend Nicholas Elliott, did Philby ever confess to spying for the Soviets, albeit partially. Shortly thereafter, he disappeared into the night onto a Soviet freighter bound for Russia, where he lived for the remainder of his life.
The signals about Philby had always been there. The Communist sympathies from his years at Cambridge, a first marriage to an Austrian communist. The system saw it all and, time and again, cleared him of any suspicion or wrongdoing.
This is not an article about mid-20th-century espionage. This is about what happens when a system has to verify something for which it has no reliable ground truth for, using signal that captures what to look for, but not how to weigh it.
What this has to do with AI
There’s a funny conversation happening in the AI community right now. Researchers and frontier labs are increasingly dismissive of humans’ ability to verify or review long-horizon tasks, but are also insistent that human data is what unlocks the next 1000x in model capabilities. Both are probably true statements, but they point to two different problems getting collapsed into one.
The first is bandwidth. A human cannot sit through a four-hour agent trajectory, follow every tool call, and reliably verify the work to a high degree of accuracy. But this is a solvable problem, whether it be through better tooling, sampling, or even breaking longer tasks into smaller checks.

The second is criteria. In unverifiable domains, where there’s often no clean ground truth, two qualified experts can review the same output and disagree on whether it is good. Not because one of them is wrong, but because “good” is a judgment call, and judgment calls don’t average across annotators the way correctness does.
This is the harder problem to solve. In unverifiable domains, the verifier is not approximating a ground truth because there isn’t one. The verifier is somebody’s weighting of criteria, which means in unverifiable domains, the verifier is taste.
Taste isn’t one thing
When most people talk about taste, they treat it as a single thing, but in reality, taste has two parts, each of which behave very differently.
The first is criteria. The line items and properties in a rubric that dictate when an agent’s output is considered good. For a legal brief, that might look like:
A clear issue statement that frames the legal question
Citations to controlling authority
A coherent narrative spine that connects the facts to the legal argument
Criteria is mostly binary, in that either the brief cites the right cases or it doesn’t. Either the brief is succinct or it isn’t.
On criteria, MI6 had Philby cold. The Communist circle at Cambridge, the first marriage to an Austrian communist, the Cambridge friends who had already defected to Moscow. All of it was in his file, surfaced and reviewed more than once. MI6 had the rubric, and it scored him on the rubric.
What it didn’t have was an answer to the next question. Confronted with a Cambridge man, the son of a celebrated Arabist, decorated in the war, vouched for by the right people, what do you do with the red flags? Every time MI6 ran the question, it answered the same way: down-weight them.
That next question, what to do with the line items when they coexist, conflict, or trade off against each other, is weighting. Weight is continuous, context-dependent, and the harder half of the problem of capturing taste.
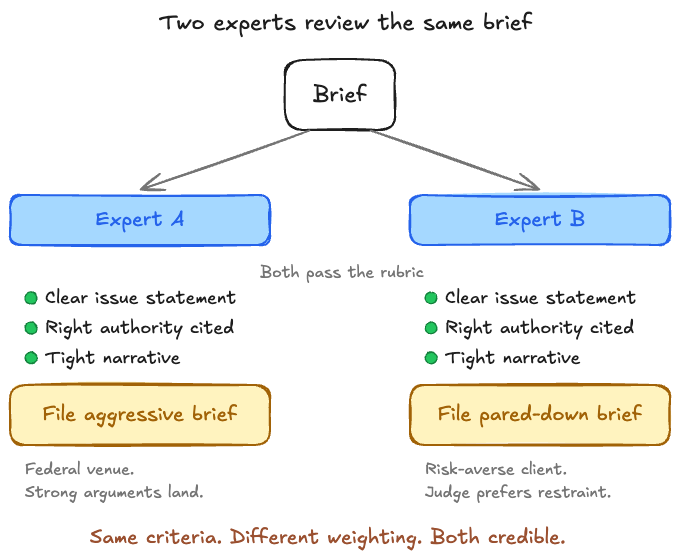
For example, two experienced litigators can sit down with the same case and agree on every criteria. Both want a clear issue statement, both want the right authority cited, both want a tight narrative. But they will disagree on whether to file an aggressive version of the brief or the pared down version. The disagreement is about how to weigh the criteria against each other relative to a specific context: a specific judge, venue (e.g., local vs federal court), client’s risk tolerance, etc. The end result is you still have the same rubric, but different verdicts.
The human data machines today are quite good at the first half via pairwise preferences, rubric annotation, etc., but none of it captures the trade-off logic that turns items into a verdict.
Why aggregation doesn’t rescue this
The obvious objection at this point is that we already have a tool for this. RLHF works by collecting preference pairs from many annotators. If you collect enough of them, the model is supposed to learn the implicit weighting through statistical aggregation. Surely scale solves the problem then?
It doesn’t, because aggregation captures the median annotator’s weighting in the typical or average context, which, for unverifiable domains, is what you want to avoid.
Value in unverifiable domains comes from non-median judgment applied to non-typical context.
A great legal brief isn’t the median lawyer’s brief. A great research direction isn’t what most reviewers would pick. A good investment thesis is, almost by definition, one most people disagree with at the time of the trade. The whole point of bringing in expert judgment is to access the part of the distribution that consensus would smooth away.
When you average preferences across annotators and contexts, you smooth out the signal that distinguishes good from average judgment. You don’t end up with a verifier that approximates expert judgment. You end up with one that approximates consensus annotator judgment, and those are different things.
 small resolution.jpg - Wikimedia Commons")
Let’s imagine we ran this on approach on Kim Philby. A vetting model trained on the aggregated preferences of every MI6 officer in 1945 would have produced exactly the verdict the system produced: he’s one of us, the signals pointing the other way must be noise. More annotators wouldn’t have helped. The signal was in the minority weighting that aggregation washed out.
In unverifiable domains, the value of a verifier - taste - is precisely what aggregation destroys.
The real question stops being “more data”
So if aggregation is the wrong tool, the question stops being how to collect more preferences and starts being something harder. What are we actually trying to capture in unverifiable domains?
The hypothesis: somebody’s weighting of legally-defensible criteria, in specific contexts, captured at high enough fidelity that a verifier can apply it when the context shifts. That reframe forces two questions.
The first is whose weighting. Ideally, it would be experts whose judgment correlates with real, measurable outcomes in the domain in question. Obviously, that is far from simple.
Outcomes in unverifiable domains are often delayed, noisy, or unobservable. For example, reputation is a proxy and a weak one; it tracks visibility as much as judgment. Peer consensus often selects for orthodoxy, which is the opposite of what makes expert judgment valuable in the first place. Philby’s career is a textbook example of this. The Cambridge education, the war record, the OBE were all layers of peer consensus pointed the same way. The jugement that would have caught him was the orthogonal kind, which peer consensus is built to surpress.
None of this means expert selection is impossible. It means it’s a real problem that has to be solved, not an assumption that can be hand-waved past.
The second is how to capture it. Pairwise preferences flatten weighting into a single binary signal. Rubric scoring captures criteria but skips the trade-off logic. What you actually need is closer to reasoned disagreement at depth: experts not just picking the better output but explaining what they would have prioritized differently, in what context, and why. The trade-off logic itself becomes the training signal.
It should be said however, that this is dramatically harder to scale than what we have today. The whole appeal of pairwise preferences was that they were cheap and parallelizable. Weighting capture is neither. It requires more time, more expertise, and more thought per data point.
This is where approaches like throwing more data at the problem start to break down. You don’t need more data, you need different data, from different people, captured in different ways.
The last mile keeps moving
Aaron Levie made a point recently that connects directly to this. As agents get better at the parts of a task they can already do well, the “last mile” - the part requiring human judgment to verify - keeps shifting up the value stack. The taste needed to verify a junior analyst’s output today is not the taste needed to verify a senior partner’s output tomorrow.
The frontier of what counts as good keeps moving, because the floor of what agents can do keeps rising.
What that means is, weighting capture isn’t simply a dataset problem. It is and will be, an evolving competency. Whatever weighting you capture today is correct for a domain that’s already moving, spurred on by AI agents. By the time the agent trained on it is deployed, the work that needs verifying has shifted, and the taste required to verify has shifted with it.
In unverifiable domains, you are not building a verifier once. You are building the capacity to keep capturing the right people’s weighting as the work that needs verifying changes underneath you.
The next 1000x in unverifiable domains doesn’t come from more taste in the data. It comes from the right people’s taste, captured at fidelity, as the frontier moves. Kim Philby walked out of his mother’s flat in Drayton Gardens in 1955 because the system optimized for the wrong taste. It had the criteria. It had the data. What it didn’t have was a way to weigh Cambridge against Moscow, before the consensus had already smoothed the difference away. The version of that problem facing AI is harder, because the frontier keeps moving and the answer keeps shifting with it. Whoever figures out how to solve the taste problem facing AI, will own it.
Vetting the file
At Collinear, we’re building part of it. SimLab is our simulation lab for AI agents: the infrastructure to generate, curate, and verify high-signal data at scale. Simulated enterprise environments, NPC users, verifiable tasks, training-ready rollouts. SimLab is built to capture expert weighting in context: not just whether an output is good, but the trade-off logic underneath the verdict, refreshed as the work itself shifts.
If you’re shipping AI in a domain where verification is hard, where median-annotator labels won’t get you there, and where consensus would smooth away exactly the signal you care about, we should talk. Every domain has its Philby. The work is building the system that doesn’t clear him.