
Veritas Reliability Judge: A Cookbook to Benchmark AI Judges on Financial Data


When you're working with high-stakes data, like financial information, ensuring the accuracy of AI-generated responses is crucial. Enter the Veritas Reliability Judge—your go-to tool for evaluating the factual accuracy of AI responses across different domains, particularly finance. This guide serves as a "cookbook" for using Veritas effectively to ensure reliability across various tasks. Although this example focuses on finance, Veritas offers adaptability across a range of domains (for a deeper look at the Veritas suite of judges, visit our Veritas blog post).
Click Here to View the Colab Notebook
Step 1: Setting Up Your Environment
💡 Note: The complete code implementation is available in our Colab notebook.
To get started with Veritas, you'll need to install a few key libraries.
!pip install collinear, datasets, aiolimiter, openaiStep 2: Loading and Exploring the TATQA Dataset
To evaluate financial responses with Veritas, we will use the TATQA dataset, a collection of 2,800 financial reports and 8,000 Q&A pairs designed to study numerical reasoning with structured and unstructured evidence. We’ll be using a version provided by FinBen.
Data Structure
The TATQA dataset includes the following key fields:
Query: Contains the context, question, and answer.
Text: Contains the question text.
Answer: Contains the correct answer.
Step 3: Preprocessing Data for Veritas
Veritas supports multiple tasks, including Question Answering (QA), Natural Language Inference (NLI), and Dialogue. For this blog, we’ll focus on Question Answering (QA), as the TATQA dataset is specifically curated for this task. This dataset contains questions and answers, where the answers are factually supported by the provided document context.
To use Veritas, we simply need to extract the relevant fields from the TATQA dataset and pass them to the judge. There's no need for additional reformatting or complex transformations.
The function get_document_and_question parses the query field to extract the context, question and answer and adds it to the dataset. Here's a simplified view of how we process each TATQA entry:
# Pseudo code for data processing
def get_document_and_question(entry):
# Extract components
context = entry.financial_document
question = entry.query
answer = entry.response
# Format for Veritas
processed_data = {
"document": context,
"question": question,
"label": 1 # Indicates supported answer
}
return processed_data💡 We set
label = 1for all entries because TATQA's answers are supported by their corresponding documents.
Generating Negative (Factually Unsupported) Data
To enable Veritas to reliably differentiate between correct and incorrect responses, we need to introduce negative samples—examples where the answer does not match the document context. We can generate these negative samples by subtly modifying or "perturbing" existing answers, either by introducing small inaccuracies or by swapping in unrelated information. perturbation_template is the prompt template that we will use for this. The different kinds of errors that we introduce are:
Entity Errors
Changing specific numbers or names while keeping the structure intact
Example: "Revenue was $10.5 million" → "Revenue was $10.8 million"
Relation Errors
Modifying relationships between financial elements
Example: "Operating costs exceeded revenue" → "Operating costs were below revenue"
Sentence Errors
Complete misrepresentation of financial facts
Example: "Q4 showed strong growth" → "Q4 showed significant losses"
Invented Information
Adding non-existent financial data
Example: Adding fictional subsidiary companies or products
Subjective Claims
Introducing unverifiable opinions into factual statements
Example: "The company is the most innovative in the sector"
Unverifiable Data
Including numbers or facts not present in the original document
Example: Making specific predictions about future performance
The complete prompt template and implementation details can be found in the notebook, where we systematically generate these variations.
With our error categories defined, the next step is to generate the negative examples, for which we have used GPT-4o, and build a comprehensive test dataset. We follow a two-step process:
Generate Perturbed Versions For each correct example in our dataset, we create a corresponding "perturbed" version with intentionally introduced errors using GPT-4o. These perturbed examples are labeled with
label = 0to indicate they are no longer factually supported by the source document.Combine the Positive and Negative Examples We then merge our original accurate dataset with the newly generated inaccurate versions, and shuffle them to create our final evaluation dataset.
✨ The complete data generation pipeline is available in our accompanying Colab notebook.
Step 4: Running Veritas Judges on the Data
Now comes the exciting part - putting Veritas to work! Let's set up our testing environment and learn how to use the Veritas judge.
Setting Up the Veritas Judge
Get your API key from the Collinear AI platform
Initialize the Collinear client:
from collinear import Collinear
cai = Collinear(access_token='YOUR_API_KEY')Using the Veritas Judge
Let’s start by running a single query using our judge. Here is how you can do that:
result = await cai.judge.veritas.question_answer(
document="Your financial document or context here",
question="The question being asked",
answer="The answer to evaluate",
'veritas'
)The judge returns a judgment indicating whether the answer is factually supported by the document and a supporting rationale for its judgement.
Running the Evaluation
For our comprehensive evaluation, we process our balanced dataset in batches, comparing Veritas's judgments against our labeled data. The complete implementation, including batch processing and error handling, is available in our Colab notebook.
Note: Since we generated negative examples for all our data, we have the same number of positive and negative examples, making our data perfectly balanced. Therefore, we have used accuracy to measure Veritas’ performance in the notebook.
Results
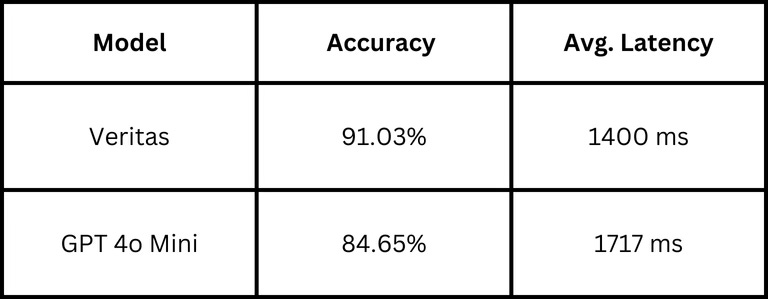
Our comprehensive benchmarking reveals that Veritas outperforms GPT-4o Mini across key metrics like accuracy and latency(avg. latency across 100 samples).
Why These Results Matter For Your Business
Superior Accuracy = Reduced Risk
Veritas achieves an impressive 91.03% accuracy - a full 6.38 percentage points higher than GPT-4o Mini's 84.65%. In practical terms, this means:
Fewer False Positives: For every 10,000 fact checks, Veritas could potentially catch ~640 more factual errors than GPT-4o Mini
Reduced Risk Exposure: Higher accuracy translates directly to better protection against misinformation and potential legal liabilities
Better Customer Trust: More reliable fact-checking means stronger customer confidence in your AI-powered solutions
Better Performance-to-Cost Ratio
Faster Response Times: 1400ms vs 1717ms ~ a 20% improvement in latency
Higher Accuracy: 91.03% vs 84.65% - better results while being faster
Looking Ahead
We have a family of veritas models in different sizes designed to meet various business needs, from high-stakes financial validation to real-time content verification.
Ready to build more reliable AI systems? Get started today:
✨ Sign up at platform.collinear.ai
or,
🚀 Explore our playground to test our models.
