
Through the Valley of Reasoning: What Small Models Teach Us About Learning
NeurIPS paper on knowledge distillation scaling laws for small foundation models




tl;dr: When distilling reasoning into small models, performance doesn’t rise smoothly with more data. Instead, it first drops before steadily climbing again. In the “valley”, small models learn more from easy problems than hard ones and are insensitive to whether training outputs are correct.
Read the paper and reproduce the results with our dataset on HuggingFace 🤗 (approx. 300M tokens).
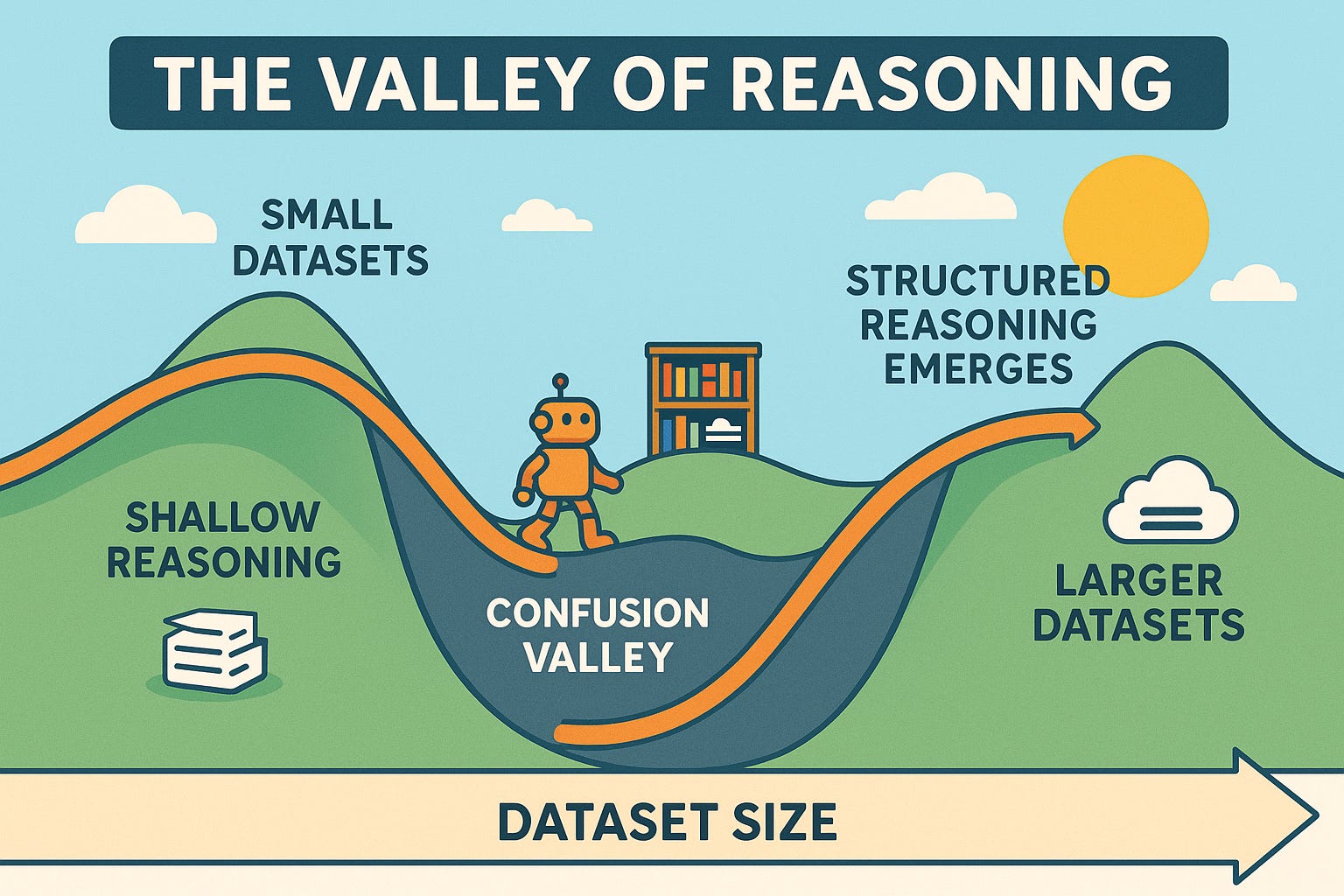
When we train small language models to reason on code, their performance doesn’t just rise with more data, it first falls into a dip before climbing back up.
We call this the Valley of Code Reasoning.
The Dip Before the Climb
Distilling the reasoning traces of large models into smaller ones has become a popular way to unlock coding or reasoning skills without huge compute budgets. But when we tracked performance as we scaled up distillation data, we found a non-monotonic trend:
With small amounts of data, models retain shallow skills.
As we add more, performance drops, a confusion stage where models are struggling to restructure their internal representations.
Only after passing through this valley do they climb back up, showing steady log-linear improvements.
This valley is a structural feature of how small models learn reasoning.
What We Learned in the Valley
We fine-tuned models at different points in this curve and found two surprising results:
Easy problems matter more than hard ones in early stages. Small models learn best by first stabilizing on simple patterns before moving up in difficulty.
Correctness of outputs didn’t matter. Training on correct vs. incorrect code traces made little difference. What mattered was the structure of the reasoning steps themselves.
Why It Matters
The valley of code reasoning reframes how we think about training dynamics: adding more data isn’t always a straight path upward. Scaling laws for knowledge distillation of small language models differ from standard monotonic scaling laws. There are two phases of learning. In the valley phase, non-reasoning models learn the structure of reasoning and so the correctness and semantics matter less. Thereafter, the models start learning from content and that’s where the difficulty and correctness starts to matter. For practitioners and researchers, this means that getting the right data for the right stage is critical.
What’s Next
If you are mid-training or post-training models or agents, connect with us and we will accelerate your time to next improved model ✨
Learn how ServiceNow is improving Apriel-1.5-15B-Thinker with Collinear curated data.
If you build off our work or use the dataset, please cite us:
@article{HeShafiqueKumarMackeyRajani2025,
title = {The Valley of Code Reasoning: Scaling Knowledge Distillation of Large Language Models},
author = {Muyu He and Muhammad Ali Shafique and Anand Kumar and Tsach Mackey and Nazneen Rajani},
journal = {arXiv preprint arXiv:2510.06101},
year = {2025},
url = {https://arxiv.org/abs/2510.06101}
}