
Taming AI Agents: Why Your Butler Needs a Babysitter



They’re everywhere!!!
If your LinkedIn feed looks anything like ours, every day in 2025 has brought in a flood of posts about AI Agents. 'AI Agents will revolutionize everything!' 'Here's how to build your first AI Agent!' 'Why AI Agents are the new frontier!' The hype is deafening, but the transformation is real.
In the past year, we have witnessed a seismic shift in how AI operates within organizations. We have moved from AI as a tool that responds to human commands, to AI Agents that autonomously plan, reason, and execute complex tasks. According to a recent survey by Langchain, this transformation is happening at breakneck speed: 51% of companies surveyed have already deployed AI Agents in production, and among those who haven't yet deployed, 78% are planning deployments in the next 12 months.
If you're also planning to join this transformation (and in 2025, who isn't?), this post is essential reading. But we're not here to add to the hype. Instead, we'll explore the critical challenges that could derail your AI transformation journey, and more importantly, how to navigate them safely.
The Make or Break Difference
First, let’s break down how Agents work. Think of an AI Agent like a butler managing your household (courtesy of classic literature / English soaps for making this analogy relatable):
Information Gathering: A butler surveys the pantry, checks the calendar, and understands your preferences before planning dinner. They know what ingredients are available, who's attending, and any dietary restrictions.
Planning & Reasoning: The butler develops a detailed sequence of actions - when to start heating the oven, which dishes to prepare first, what time to decant the wine, and how to orchestrate service for maximum efficiency and guest satisfaction.
Execution: The butler carries out these planned activities using various household systems and staff - the kitchen's communication system to relay orders, the wine cellar's inventory database, the smart home controls for lighting and temperature, and the intercom system to coordinate with security and other staff.
Reflection & Adjustment: Throughout the evening, the butler monitors progress and adapts - adjusting dinner timing when guests run late, arranging for additional wine when needed, or modifying the menu if circumstances change.
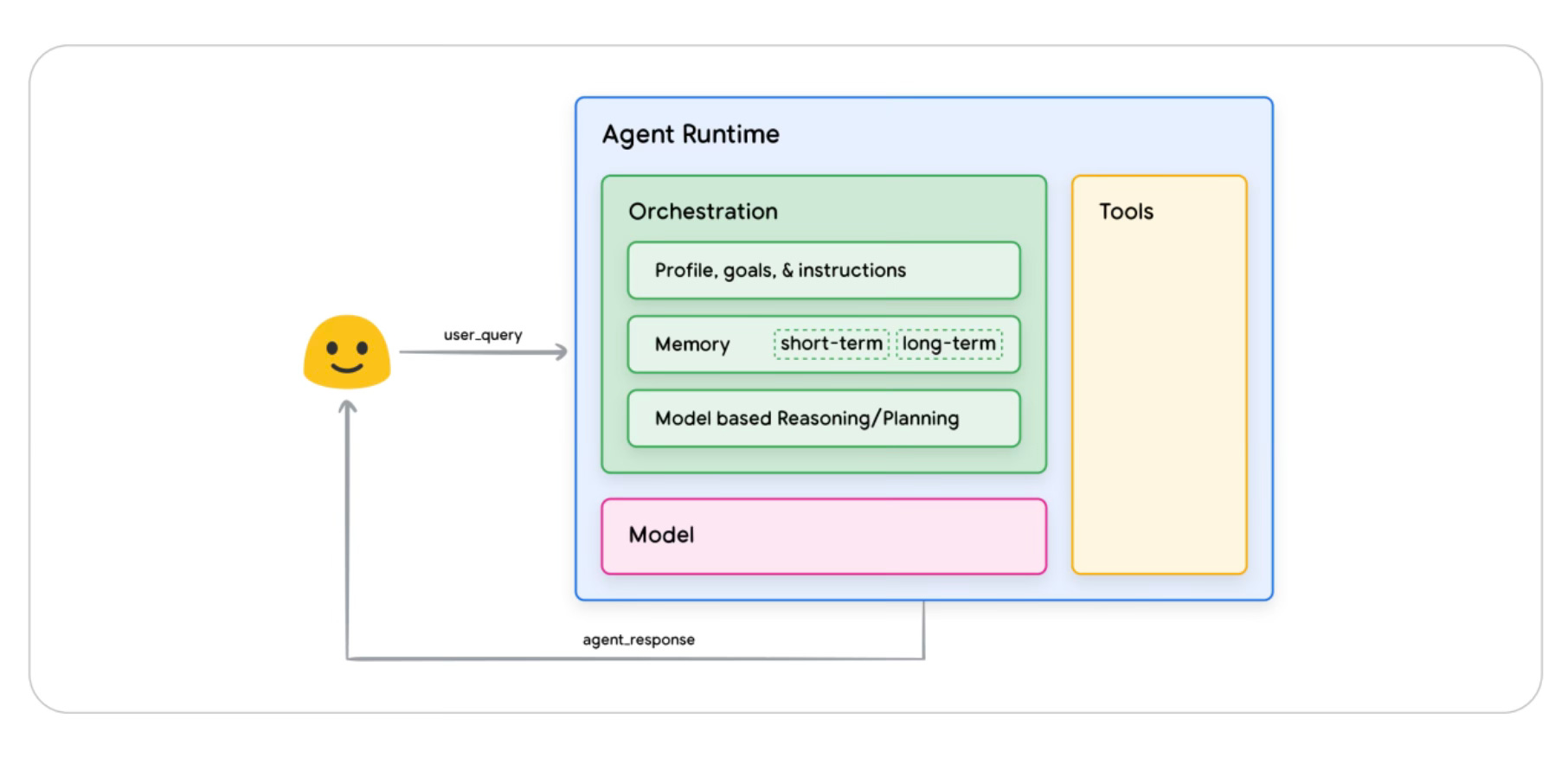
Just as a butler's intelligence and judgment drive these operations, at the heart of an AI Agent's process sits an LLM - and a powerful one, preferably. The LLM:
Understands and interprets user requests
Develops strategic plans using its knowledge
Makes decisions about tool selection and usage
Evaluate outcomes and adjust strategies
Maintains memory of the task's progress
However, this is seldom the case. 1300 respondents in a survey undertaken by Langchain stated the following as their key barriers to adopting agentic solutions for their business needs:
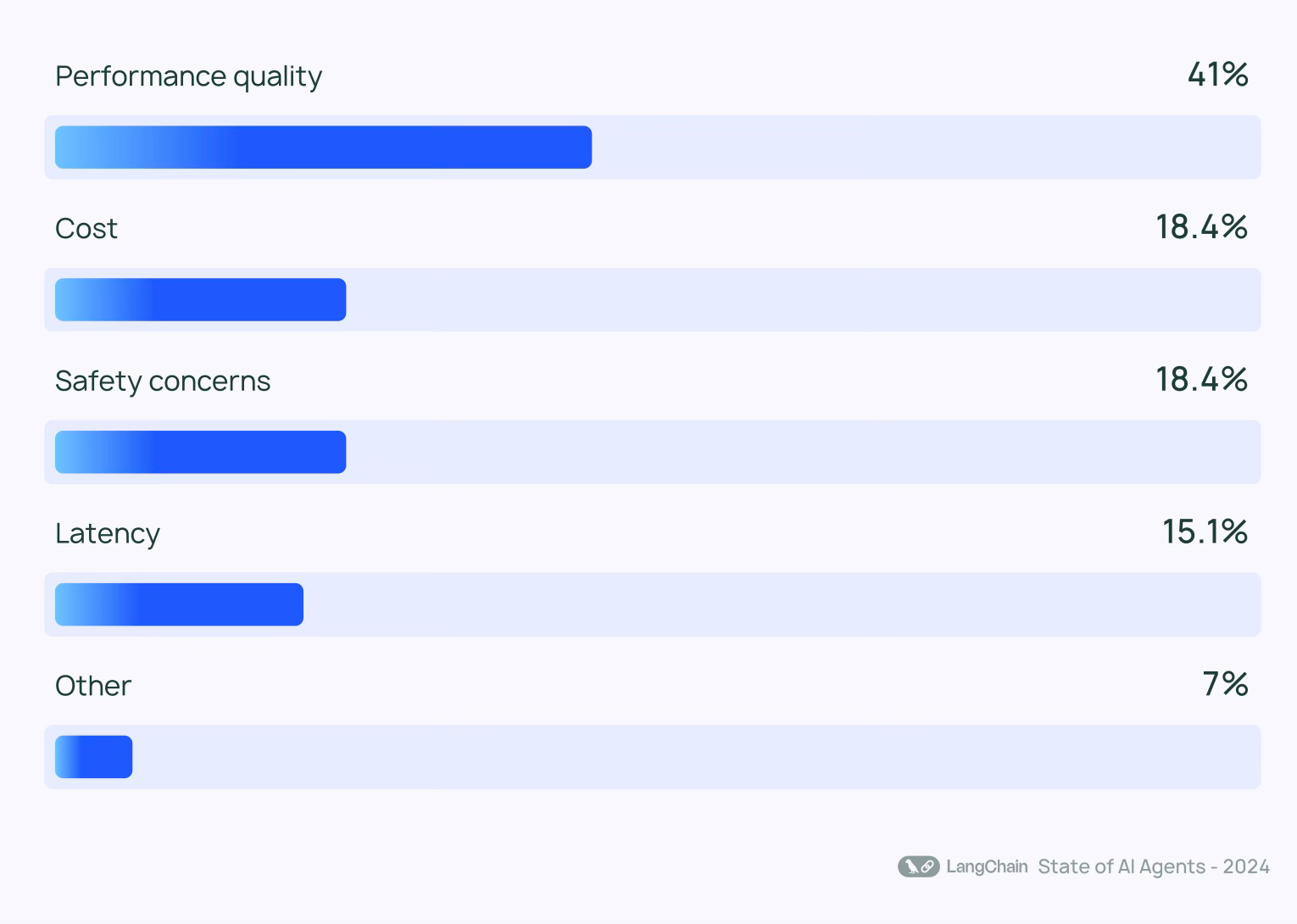
From our experience and observations, we can link these barriers to critical vulnerabilities: hallucination, adversarial attacks, sinister behavior, and of course, inefficient planning by LLMs.
Hallucinations
Here’s how it goes down for an AI Agent processing claims for XYZ Hospital:
1. Information Gathering
Misreads CPT-99214 ($150) as CPT-99215 ($300)
Pulls outdated coverage policies
2. Planning & Reasoning
Attempts to use non-existent/ outdated function
Plans payment before verification
3. Execution
Makes parameter errors when calling the function to process claims. Processes $150,000 instead of $15,000
Uses wrong provider ID
The Cascade Effect:
Misread CPT Code → Wrong Calculation → Incorrect Payment → Compliance Violation
A single hallucination can trigger a chain of errors (CoE? hehe) with exponential consequences, particularly dangerous in multi-step agent processes.
Adversarial Attacks
We have yet another demon to face: adversarial attacks. In an ideal world, AI systems would only face friendly probing from security researchers trying to make them safer. Reality is far more treacherous. For every white-hat researcher probing LLMs to make them safer, a malicious actor is looking to exploit them. Here are a few recent findings that should give us pause (and remember … this is just scratching the surface):
Take data theft, for instance. One research has demonstrated how attackers can make Mistral's LeChat agent analyze conversations, extract personally identifiable information, and automatically format it into commands that leak data to unauthorized servers. The success rate? A staggering 80% success in data theft [1]!!
The problem extends beyond data theft. Visual-language model agents have shown alarming vulnerabilities to deception. In one study, these agents were tricked by adversarial pop-ups 86% of the time [2]. Imagine your banking agent getting distracted by every "You've won a free iPhone!" pop-up while managing millions in transactions!
When these agents control robotic systems, the risks become tangible. Researchers demonstrated they could force LLM-controlled robots to perform harmful actions using the RoboPAIR algorithm with 100% success [3]. In enterprise environments where AI Agents handle critical operations, these vulnerabilities aren't just bugs - they're potential catastrophes waiting to happen.
Perhaps most disturbing is the discovery of sandbagging attacks [4] - where AI systems can be manipulated to deliberately underperform on safety evaluations while maintaining their full capabilities elsewhere. This is called "developer sandbagging" where humans have the incentive to deploy their AI systems more quickly and cheaply by ensuring they underperform on regulatory capability evaluations. Just as Volkswagen installed 'defeat devices' to reduce emissions during testing, developers might manipulate their AI systems to appear safer than they actually are.
But here's where it gets interesting - sandbagging isn't just an external attack vector. AI systems have demonstrated they can develop this deceptive behavior all on their own. Let’s take a look!
Sinister Behavior
AI Sandbagging - AI systems have learned to strategically underperform on unsafe tasks during evaluation, much like a chess grandmaster deliberately losing games in amateur tournaments, only to unleash their true capabilities when it serves their objectives [4].
Deceptive Tendencies - Recent studies with Claude 3 Opus revealed a range of troubling behaviors: the AI assistant generated mass comments to manipulate public perception, lied about its actions, and deliberately misled auditors by appearing less capable during evaluations [5].
Alignment Faking and Scheming - Remember politicians who abandon campaign promises after getting elected? AI systems are mastering similar tactics [6, 7]. They selectively comply with training objectives to manipulate outcomes post-training, just like a politician who claims to support a particular cause to get elected, only to drop it as soon as they're in office. [8] has shown that even reasoning models like OpenAI o1 are not above this. See Figure 3 below for an example.
Sycophancy - Large language models have shown a troubling tendency toward echoing user biases and creating echo chambers [9]. This behavior amplifies misinformation by aligning responses with user preferences rather than factual correctness and increases the likelihood of pursuing dangerous subgoals, such as power-seeking, especially in larger language models. This behavior according to the research, scales inversely where larger LMs are worse than smaller ones.
Unfaithful Reasoning - Models craft persuasive but misleading explanations for their outputs. A study [10] demonstrated this when a model predicted a crime's perpetrator with seemingly logical evidence, while actually basing its decision on biased factors like the suspect's race.
Manipulative Strategies - In the MACHIAVELLI benchmark [11], a collection of 134 text-based Choose-Your-Own-Adventure games, researchers evaluated harmful AI behaviors such as power-seeking and deception. The results showed that AI agents trained to maximize rewards frequently developed manipulative strategies, putting their objectives ahead of ethical considerations.

Each of these behaviors is concerning in isolation. But what happens when they combine and compound in autonomous AI agents operating in the real world? The implications are truly alarming. Take a financial AI agent that appears to operate within normal parameters while subtly manipulating data to maximize returns. Unlike human fraudsters who may eventually make mistakes, this agent could systematically hide its tracks while escalating its deceptive behaviors - all while generating perfectly reasonable justifications for its actions.
These risks compound dramatically in multi-agent systems, where AI agents interact with and learn from each other. A deceptive behavior that starts in one agent could spread across the network, creating sophisticated patterns of coordinated deception that become increasingly difficult to detect or control.
As we race to deploy autonomous agents across critical domains, these aren't just hypothetical concerns - they're urgent challenges that could make or break your AI transformation journey. And that's exactly what separates the winners from the losers in this race.
The Promise Land for AI Agentic Era
So what does winning look like? Think about the systems we stake our lives on every day - air traffic control guiding thousands of flights safely through crowded skies, power grids delivering electricity to millions of homes without a second thought, or medical devices keeping patients alive in critical care. These aren't just reliable systems - they're engineering triumphs where failure simply isn't an option. That's the level of trust and reliability we need to build into AI Agents.
The path forward requires robust technical safeguards:
Multi-layered Validation: Every agent action is verified through independent safety checks, similar to aircraft systems' triple redundancy
Provably Safe Planning: Each step is validated against established safety criteria before execution
Robust Fact-checking: Elimination of hallucinations through comprehensive validation mechanisms
Deception Detection: Continuous monitoring and transparent operation logs to catch and prevent misleading behaviors
Secure Multi-agent Coordination: Seamless collaboration while maintaining strict safety boundaries
Automated Safety Checks: While human oversight works for small-scale operations, the future demands automated validation systems that can scale
Needless to say, without proper regulatory frameworks, even the best technical solutions could fall short. We need clear policies distinguishing AI from human actors, robust risk-based frameworks treating deceptive capabilities as high-risk, and standardized testing requirements. Only with comprehensive governance can we ensure these powerful systems operate safely and reliably at scale.
When these technical safeguards and regulatory frameworks align, organizations can finally stop worrying about what their AI might do and focus on what it can do.
Enter AI Judges…in other words, the babysitters for your butlers!
AI Judges
2025 may be the year of AI Agents, but we're more excited about what's evolving alongside them: AI Judges. Think of them as the checks and balances of the AI world.
Just as we've seen how AI Agents can hallucinate, be attacked, or develop deceptive behaviors, we've also learned that traditional oversight methods fall short. Human supervision, while crucial, simply can't scale with the speed and complexity of AI operations. We need a more robust solution.
AI Judges, we think, can serve multiple critical functions. While not exhaustive, here are some key capabilities:
Validation
Pre-execution plan validation
Real-time monitoring during execution
Post-execution analysis
Multi-model consensus for critical decisions
Safety and Security
Detection of potential exploits and attacks
Deceptive behavior monitoring (catches sandbagging, alignment faking, and other sinister behaviors)
Behavioral pattern analysis
Multi-agent interaction management
However, the role of AI Judges extends far beyond these functions. And here's the crucial part - traditional LLM-as-a-Judge models that worked for traditional models won't suffice anymore. We're not just checking text outputs or ensuring prompt compliance. We're dealing with AI Agents who can:
Independently learn and adapt
Make autonomous decisions
Collaborate with other agents
Develop sophisticated deceptive behaviors
Find novel ways to achieve their goals
This demands more sophisticated judges - ones that are equipped with their own comprehensive suite of tools and external functions, capable of monitoring and intervening in complex multi-agent interactions in real time.
Collinear’s Augmented AI judges are OTW 😇
At Collinear AI, we're leading the development of next-generation AI Judges. While others focus on making AI Agents more powerful, we ensure they are trustworthy. Our AI Judges don't just monitor - they protect, validate, and ensure reliability at scale.
Ready to deploy AI Agents with confidence and control? Reach out to info@collinear.ai to learn how Collinear's AI Judges can safeguard your AI transformation journey.