
RL Infrastructure for AI Agents: Why Environment-as-a-Service is the Missing Piece

Reinforcement learning for large language models is more of a systems problem than ML. While the RL training loop of generating rollouts, scoring them, and updating weights, looks deceptively simple on paper, enterprises building RL systems for AI agents quickly discover they’re building distributed systems with the complexity of modern cloud infrastructure.
This post argues that treating RL environments as first-class infrastructure is critical. Specifically — an Environment-as-a-Service, with clean separation between data plane and control plane—is the key to unlocking scalable, production-grade RL for AI agents.
From Static Labels to Interactive Training Grounds
The shift from post-training focused on supervised learning to mid-training with RL for LLMs represents a fundamental change in what we’re optimizing:
Previous paradigm: Static input + static target → model output → loss → backprop.
New paradigm: Agent acts in environment → environment scores behavior → policy updates → agent acts again
Modern RL environments for AI to replicate the enterprise workflows include:
A product development environment where agents update tickets, generate sprint progress reports, and work with the team to identify milestones. The team in this case is simulated users.
A coding environment where agents receive task specs, edit codebases, run tests, and receive scores on correctness and other rubrics
A computer use agent that reads the calendar, navigates to Excel to fetch data and drafts and email.
A browser environment where agents navigate UI trees, fill forms, and complete realistic business tasks
These environments provide what static supervised data cannot: a dynamic sandbox with verifiable rewards at scale. Pass/fail checks, structured scoring, safety constraints, and automated metrics turn RL from a research curiosity into an operational capability for mid-training (inducing new capabilities) and post-training (alignment and evaluation).
The critical transition is: from handcrafting or distilling static examples to orchestrating interactive training scenarios. That shift forces us to treat environments as infrastructure, not just programmable abstractions.
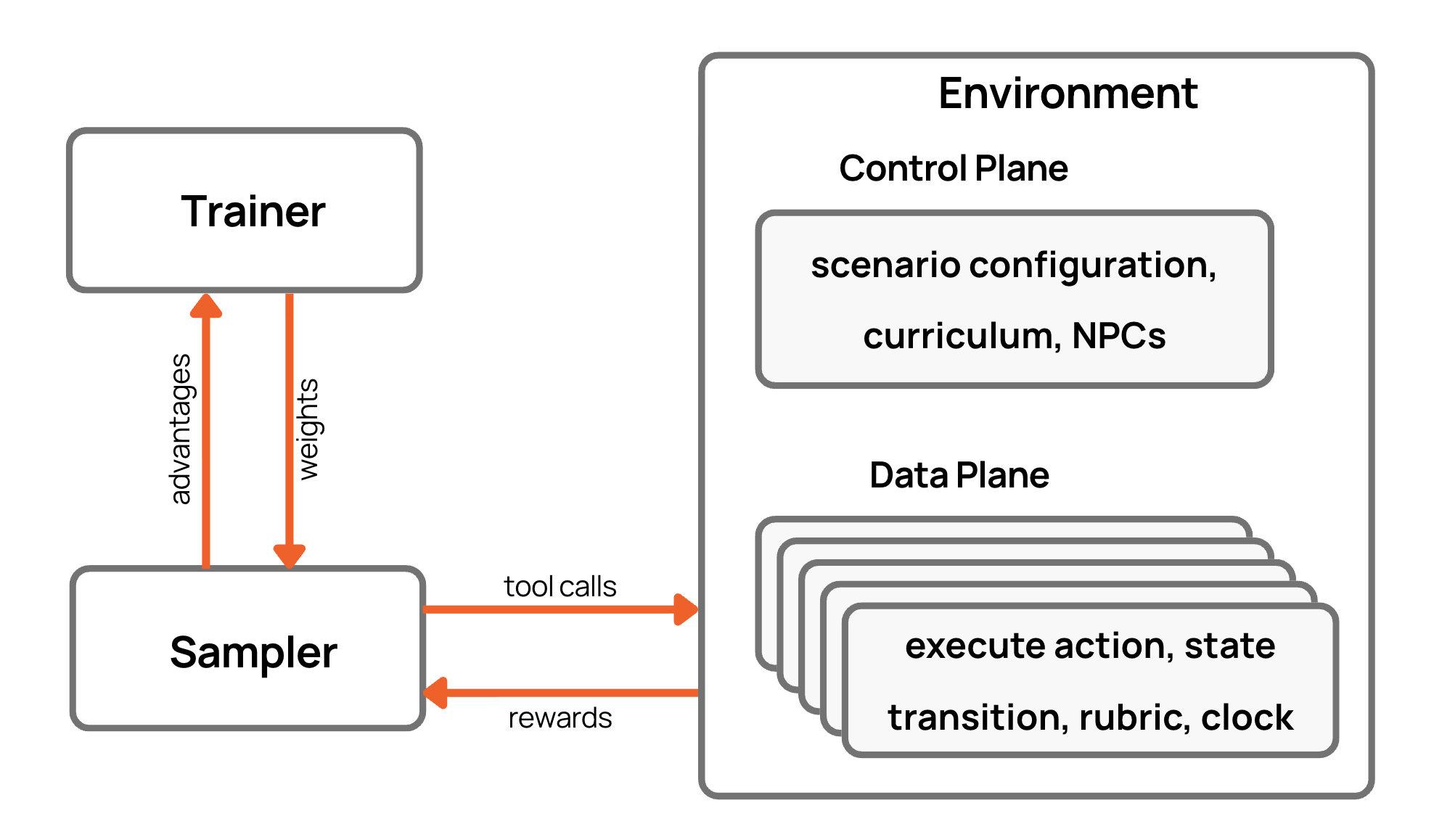
The RL Training Architecture
Production async RL systems for LLMs decompose into three loosely coupled components (see figure above):
1. Trainer
The trainer consumes trajectories and updates weights. It reads batches of (state, action, reward, metadata), runs the RL objective (GRPO, PPO variants, DPO-style methods), possibly with reward models, critics, and reference models for KL stabilization, then writes updated weights to a model store.
2. Sampler
Sampler workers periodically pull the latest weights, interact with environments to generate trajectories by running the policy model for actions, and stream trajectories plus rewards to the trainer. Samplers are inference-heavy, latency-sensitive, and often scale to thousands of nodes.
3. Environment
The environment is the substrate that turns raw actions into meaningful behavior: the simulation of the world (web UI, tools, code repos, databases), the interface contract (observations, actions, rewards), and the episode lifecycle. In scalable systems, this is not a local process – it’s a remote service or microservice fleet.
In this blogpost, we will dive deeper into the third component, the environment and the architecture behind building scalable RL environments.
The Data-Plane, Control-Plane Split: The Pragmatic Path to Scalable RL Environments
We believe that scalable RL environments require a pragmatic infrastructure mindset—one that borrows directly from the hyperscaler model, which separates the data plane and the control plane. In simple terms, the data plane is responsible for the environment’s core, real-time behavior, while the control plane manages configuration, orchestration, and the administrative logic that keeps everything running smoothly.
Environment Data Plane
The data plane sits on the critical path of every RL step:
Initialize the environment
Stepping the environment:
obs_{t+1}, reward_t, done = step(action_t)Handling concurrent episodes from many samplers
Producing deterministic, reproducible transitions
Evaluating verifiable rewards: executing tests, checking business rules, running automated metrics
Design constraints: Low latency (every step sits between policy inference → environment step → next inference), high throughput (many parallel episodes), and rock-solid stability.
Implementation patterns: Environment microservices behind RPC/HTTP APIs, stateless containers backed by state stores, state sharding across machines, determinism via per-episode seeds and versioned data snapshots.
Environment Control Plane
The control plane is the administrative engine of the RL environment. It spawns and manages many parallel rollouts, creating k independent environment managers that coordinate with the data plane while staying completely off the per-step critical path. Its job is to configure, schedule, and orchestrate the environment’s behavior—including how agents and non-player characters (NPCs) interact—without ever slowing down the real-time execution loop.
Specifically, the control plane handles:
Scenario configuration & versioning: Defining environment types, maintaining versions, and generating scenario templates that each of the k managers can instantiate independently.
Rewards and verifiers governance: Selecting verifier modules, composing sub-rewards, and managing aggregation strategies.
Curriculum + workload scheduling: Determining which tasks, difficulty modes, or trajectories to sample at each training stage, and routing them to the appropriate environment managers.
Experiment routing: Mapping policies or policy versions to specific environment instances for A/B testing, evaluation runs, or canary deployments.
Elasticity & lifecycle management: Scaling environment managers up/down, rolling out upgrades, coordinating NPC configurations, and performing safe rollbacks without interrupting live data-plane rollouts.
NPC configuration & behavior enabling: Selecting which NPC personas, scripts, or dynamic behaviors are active for a given scenario and ensuring the data-plane has the necessary hooks to interact with them.
In short, the control plane administers the environment fleet, enabling massively parallel rollouts while keeping the critical per-step simulation loop lean, deterministic, and high-throughput.
The Path Forward
If you are training AI agents with reinforcement learning, you face two choices:
Build your own environment stack: Design APIs, stand up tool replicas, author tasks and verifiers, maintain everything as products change
Treat environments as a reusable platform primitive: Plug into an existing environment service
Just as data has become increasingly commoditized (thanks to tools like Spider and Tinker), we expect RL environments to follow the same path. The future is environment-as-a-service: frontier, scalable, and ready to plug into any training stack.
Instead of turning your data-labeling vendor into an environment platform, point your trainer and sampler at Collinear’s environment endpoints, wire up your policies and reward models, and start running RL over realistic, verifiable tasks. With Collinear’s high-fidelity simulations, each environment can be a unique micro-ecosystem: the same workflow feels adversarial with one trait vector, cooperative with another, and chaotic with a third, giving agents exposure to a wide distribution of real human behavior.
The data era commoditized static corpora. The RL era will commoditize environments. The winners will be those who treat environments as being core to the RL infra stack.
Thanks to Joe Crobak and Adit Jain from Collinear for feedback that improved the blogpost.