
Data Curation: The secret sauce for enterprise AI excellence
How Collinear AI's Reward Models Transform Training Efficiency and Model Performance



Imagine post-training a frontier AI model on billions of tokens only to discover that much of that data adds noise that actually hinders its capabilities. This is the reality many organizations face when relying on massive datasets. The challenge in enterprise AI deployment centers on data quality at scale. Just scaling model size and training compute leads to endless post-training cycles without any significant lift in model capabilities.
Data curation offers an alternative: instead of feeding every token into the training pipeline, you let specialized curator models sift through the information, selecting only the most high‑quality samples.
Post-training data curation is the process of systematically selecting, labeling, and filtering data with the explicit goal of improving the performance, safety, and efficiency of machine learning models. High-quality training data is essential, so focusing on curated datasets can massively reduce training costs and compute with no loss and even gains in accuracy.
The benefits of post-training data curation include:
Performance gains over unfiltered data
Savings on training compute costs
Accelerate the speed to getting the frontier model
Get the capabilities of a bigger model in a smaller model
Our solution is a reward-model-based approach to data curation, called curators, that focuses on assessing qualities that are most critical for enterprise AI development. These reward models (RMs) can be combined to create recipes for data curation that yield an improved frontier model efficiently.
How It Works
The Curator Architecture
Curators are small, specialized models trained to evaluate each sample in a dataset for specific attributes, such as correctness, quality of reasoning, coherence, readability, instruction following, complexity, etc. Unlike heuristic-based filtering, these models understand semantic quality dimensions and make intelligent selection decisions.
Collinear's curator framework employs distinct model types, each addressing different evaluation requirements:
Scoring Models
Lightweight (~450M parameter models) that score each input-output pair with continuous values. These models address both answer correctness and quality of Chain-of-Thought (CoT) reasoning, providing granular quality assessment across the full spectrum of data quality.
Classifier Curators
Larger models (~3B parameters) trained for strict pass/fail classification decisions. These models prioritize extremely low false positive rates (FPR), accepting higher false negatives to ensure only genuinely high-quality data passes through the curation pipeline.
Reasoning Curators
Specialized ~1B parameter models that evaluate internal reasoning and logical structure. These curators excel at multi-step task evaluation, particularly effective for mathematical and code reasoning chains where step-by-step correctness is critical.
List of Methods
Depending on the challenges posed by each domain, we draw on a list of methods each tailored to boost model performance:
Deduplication removes near-duplicates using similarity detection that preserves valuable variations while eliminating redundant content.
Model-based scoring replaces heuristic thresholds with intelligent quality assessment that understands domain-specific requirements.
Embedding-based methods ensure data diversity while maintaining quality standards. Rather than random sampling, curators intelligently select samples that provide complementary training signals and address specific capability gaps.
Active learning enables targeted inclusion of new or synthetic data by identifying weaknesses in current model capabilities and selecting samples that address these deficiencies.
Curation Recipe
The different curator types are systematically combined through ensemble methods that leverage their specific strengths. The data curation is set up as a rejection sampling, and so the goal is to lower false positive rates or optimize specificity. That is, it is acceptable to filter out good samples (false negatives), but never to accept low-quality samples (false positives).
The ensemble systematically drives down FPR through consensus mechanisms and adaptive weighting based on curator confidence and historical performance validation.
Case study: Math reasoning
We evaluate our math curation recipes on the NuminaMath dataset containing 800,000+ problem-solution pairs. The goal is to filter out low-quality examples while preserving diverse, high-signal data.
The curated dataset is publicly available at collinear-ai/R1-Distill-SFT-Curated. This dataset consists of the NuminaMath samples from the ServiceNow-AI/R1-Distill-SFT dataset and has features problem, solution, source, R1-Distill-Qwen-32B, R1-Distill-Qwen-32B-messages, and correctness.
We evaluated the impact of this curated data by fine-tuning two models:
12B parameter model with CPT followed by SFT: This two-step process first adapts the model to math-specific tokens and structures before fine-tuning it on task-specific instructions
A 3.8B parameter model with SFT only: This tested the value of curation without the additional CPT phase
We then evaluated both models on Math500, a benchmark designed to test mathematical reasoning and correctness.
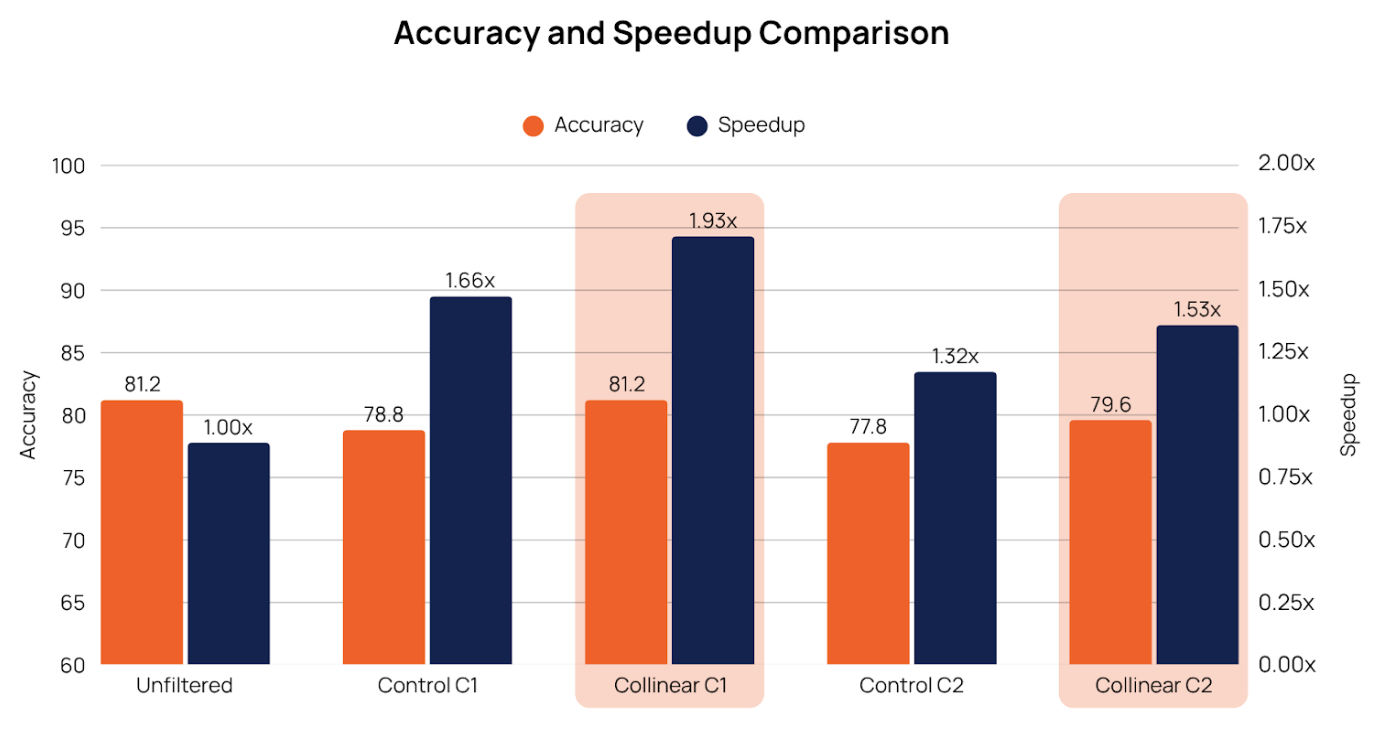
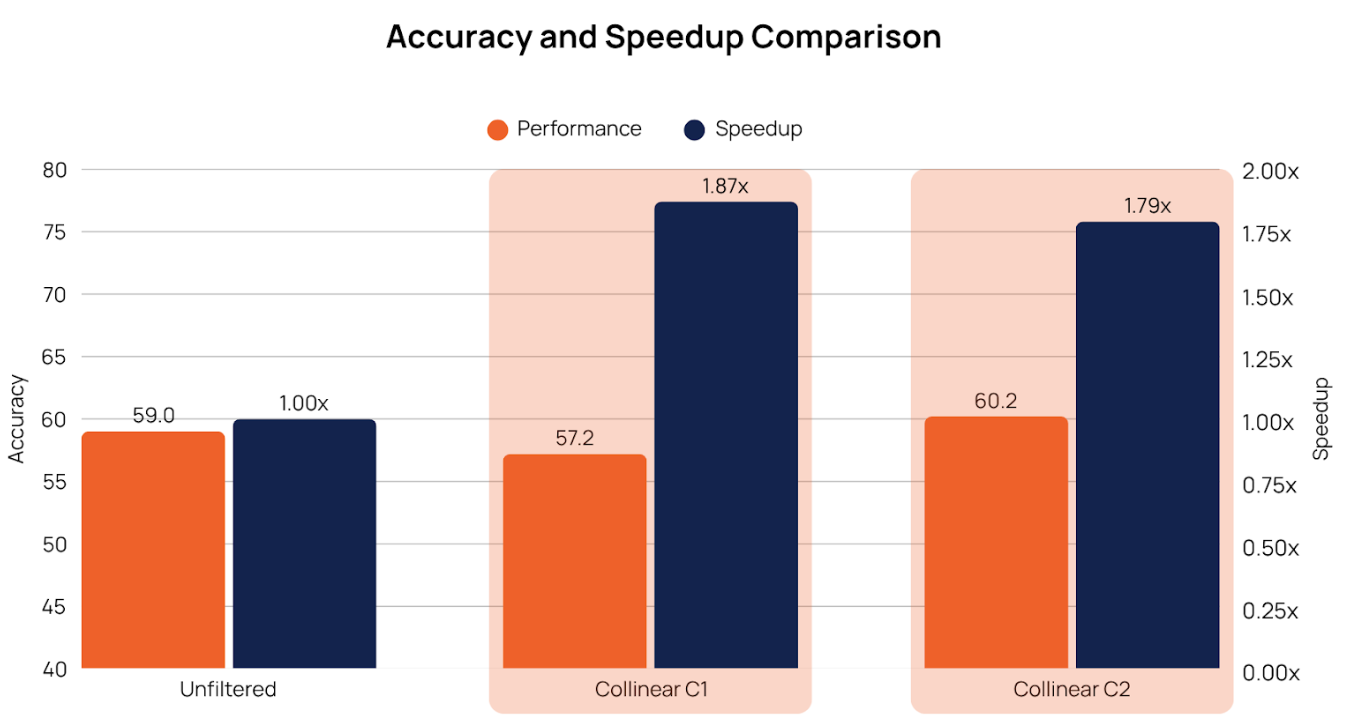
The control curated split is a random set from the unfiltered dataset of the same size as the respective curator split to establish and visualize the difference in performance. As shown, the model trained with the Collinear curated data achieved the same downstream accuracy as the model trained on the full unfiltered dataset, while utilizing less than 50% of the total dataset size i.e., ~2x speedup (measured in terms of processed tokens rather than dataset size). This demonstrates the high-quality curation provided by the Collinear curators, highlighting the effectiveness of carefully curated data in improving model performance.
Models trained on the curated dataset matched or exceeded the performance of models trained on the full dataset—while using roughly half the tokens, resulting in faster and more efficient training.
Case study: Code reasoning
We evaluate our code curation recipes on the NVIDIA’s Open Code Reasoning (OCR) corpus —739 k competitive‑programming problems harvested from CodeContest, APPS, Codeforces, and TACO. Each task comes with roughly 38 DeepSeek R1 answers (~ 8 k tokens apiece), creating significant duplication.
Curation combined our three curator models with a strict execution filter:
Semantic filter (3 curators): Classifier, Likert judge, and reward model score every answer for correctness, spec‑fit, and efficiency.
Execution filter: Run all official test cases; if fewer than 50 exist, generate synthetic tests to reach the threshold.
A pass‑only execution filter retained 72 % of answers. Adding semantic filtering removed another 62 %, leaving a concise, high‑signal 38 % of the corpus for downstream training.
To gauge the impact of data quality, we ran supervised fine‑tuning (SFT) on Qwen‑2.5‑7B‑instruct under two data regimes:
Curated: the 38 % high‑signal slice produced in Section 2.
Random: a size‑matched random slice from the raw OCR corpus.
We assessed downstream performance across four training regimes to isolate the value of Collinear’s curated data:
No training
Training on the entire dataset (unfiltered)
Control — training on token-controlled split
Execution baseline — filtering for code correctness
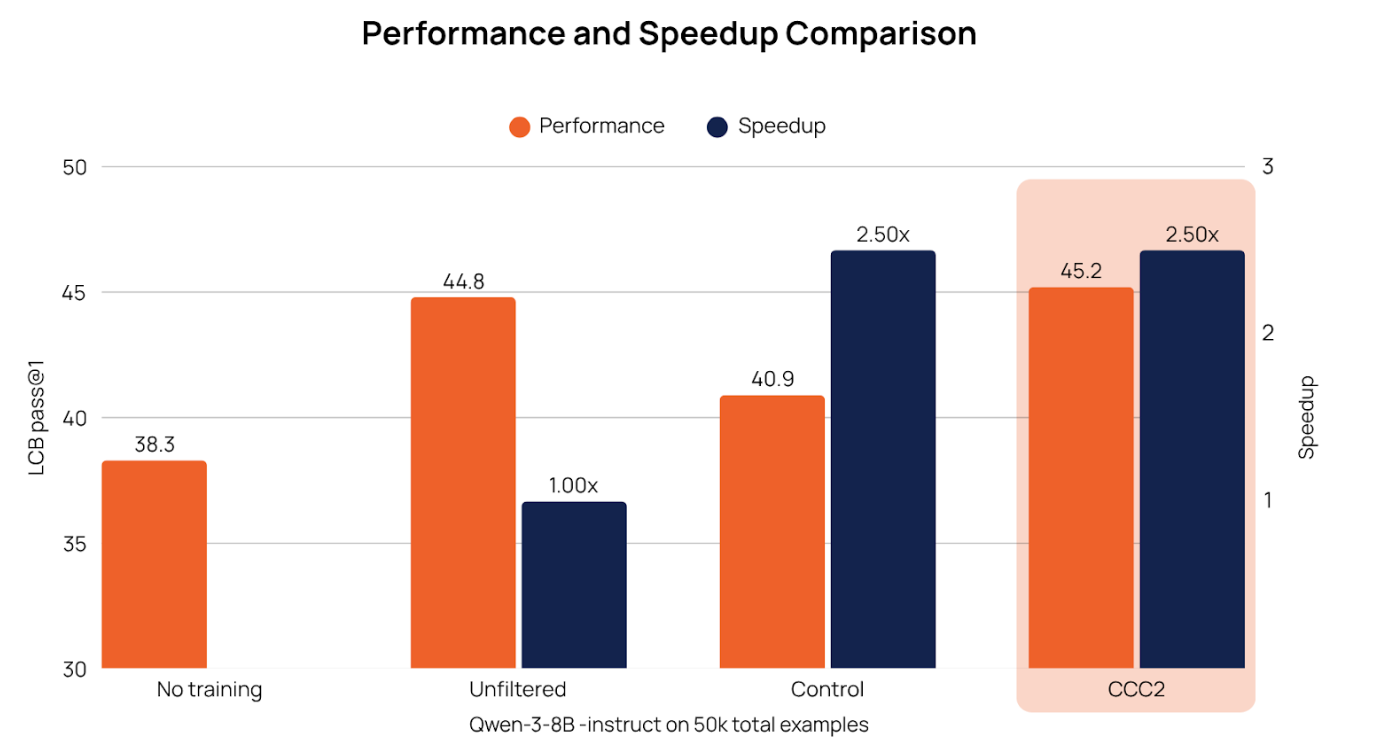
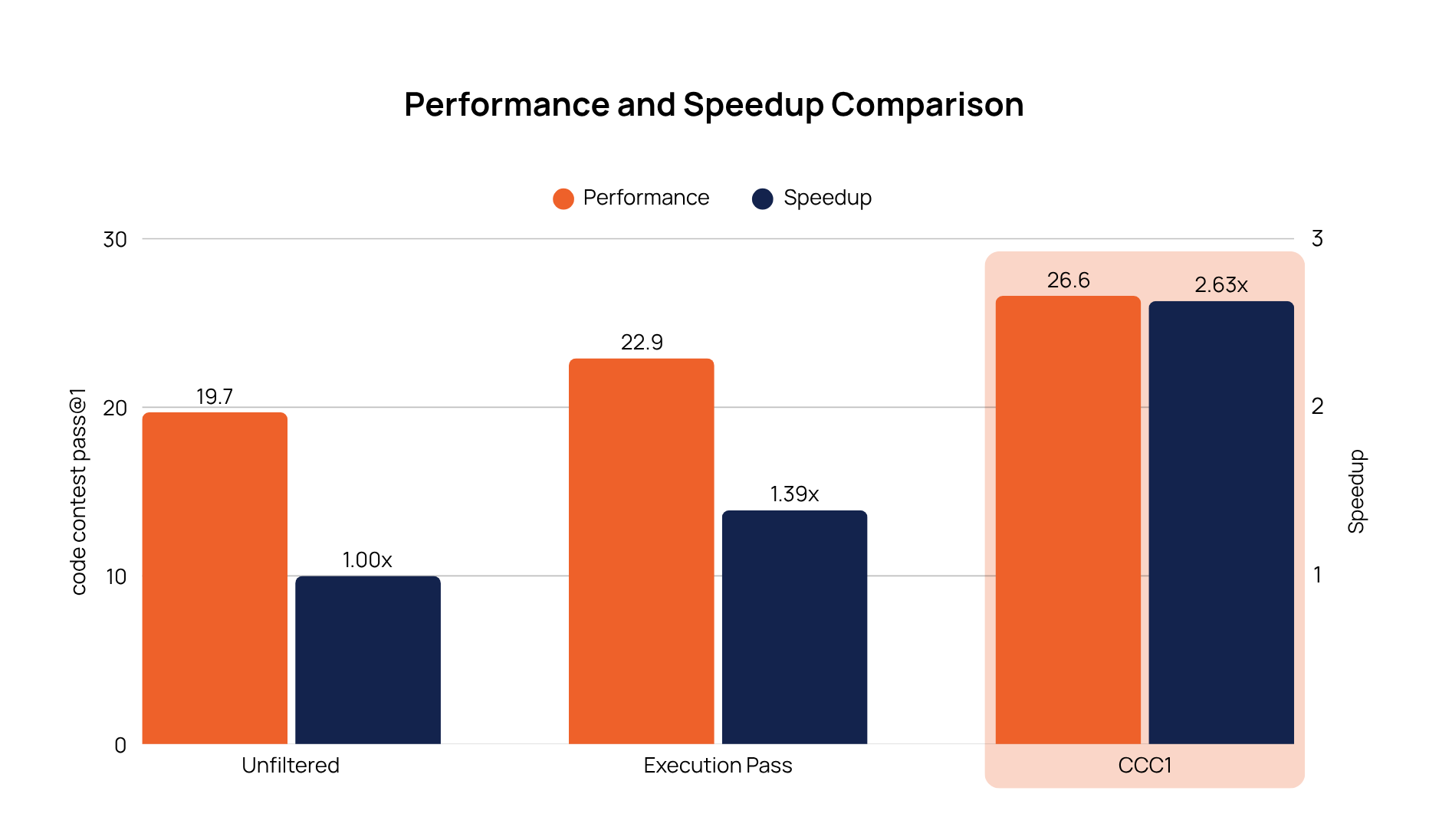
Takeaways
Data curation transforms the training process from a brute‑force exercise into a precision craft. Through specialized model architecture, ensemble methods, and rigorous validation frameworks, organizations achieve measurably superior results with dramatically reduced computational requirements. In an era where data volume alone is no guarantee of success, curation emerges as the secret sauce that elevates enterprise AI from good to exceptional.
We have partnered with F500 companies on data curation for LRMs and LLMs and showed 2x-4x speedup measured in processed tokens while outperforming or matching state-of-the-art performance. The approach enabled upwards of 50% reduction in training compute costs, representing $10M-$100M potential annual savings, not including cost saved on procuring data with human-in-the-loop processes.
Ready to start saving on post-training?
See how Collinear enables enterprises to build an AI improvement data flywheel.