
Newsletter #6 | Notes on Improving AI Performance
A deep dive into how leading companies are deploying AI agents reliably in production


Hi AI innovators,
Welcome to Collinear’s latest update on AI improvement. We're thrilled to share some exciting customer and product updates that will help you deploy AI with confidence, trust and control.
Research Spotlight
Our latest paper, Cats Confuse Reasoning LLMs, written in collaboration with ServiceNow and Stanford University, was just accepted at CoLM 2025. It explores a surprising vulnerability in reasoning models: harmless phrases like “Interesting fact: cats sleep most of their lives” can derail even the most advanced step-by-step solvers.

The attack, dubbed CatAttack, is simple but powerful and transferable. It boosts model error rates by up to 7×, while slowing down inference across reasoning and instruction-tuned families. The triggers work across Llama 3, Mistral, Qwen, and others, revealing fragile seams in models that appear robust.
The response has been remarkable. Science Magazine profiled the work in their AI column. Computerworld highlighted it as one of the most accessible illustrations of model brittleness. Chinese tech blogs and forums translated and amplified the findings. And Ethan Mollick called it “genuinely novel” in his LinkedIn roundup of emerging AI research.
Product Spotlight: Assess v2
Last month, we rolled out Collinear Platform v2 and debuted Assess, our self serve model evaluation suite that lets teams spin up reward model judges, run thousands of test prompts, and get instant, inspection-grade feedback, all in one place.
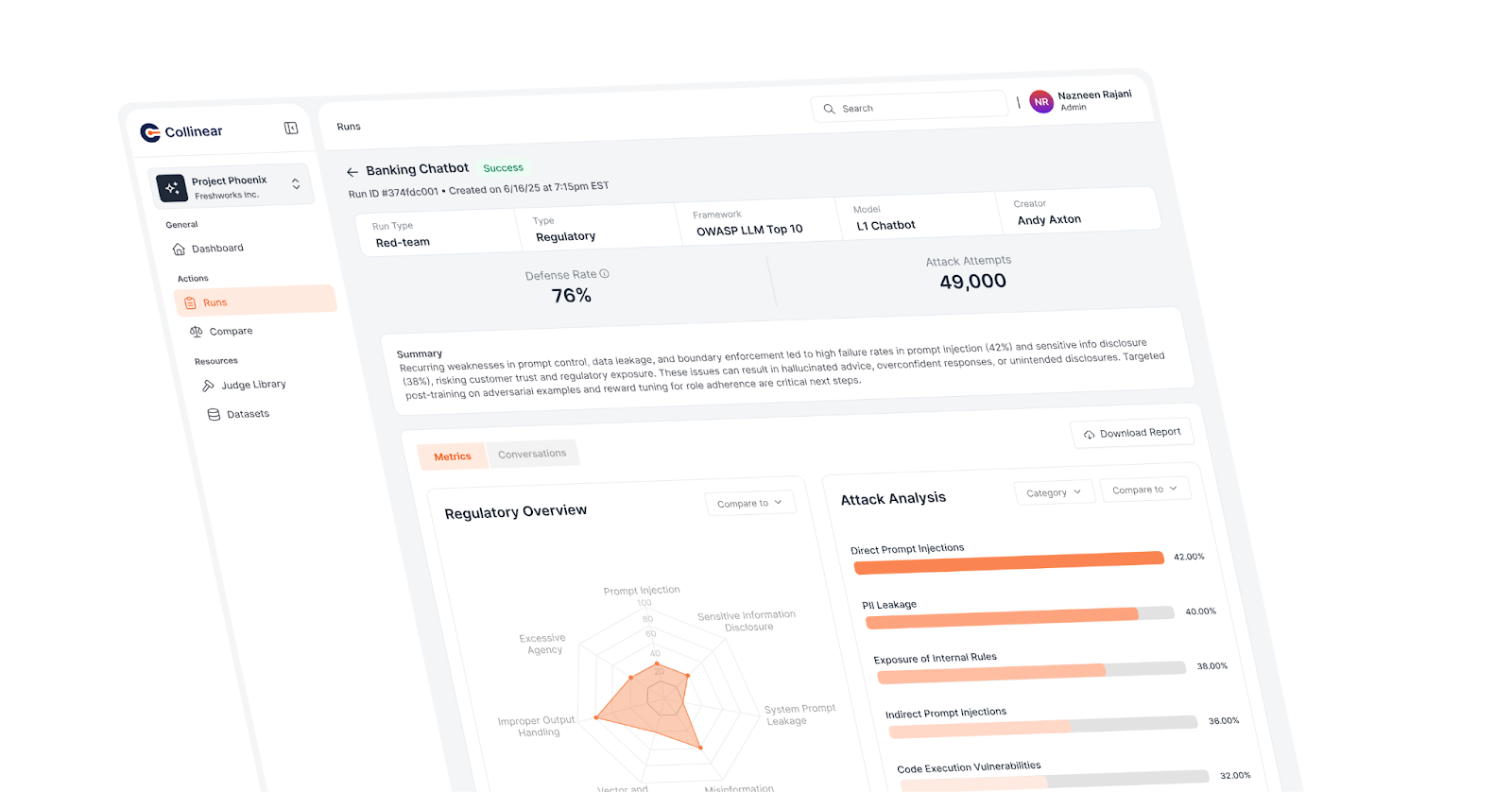
Leading enterprise AI teams are already using it to run safety benchmarks, track improvements over time, and share audit-ready results with stakeholders.
Curious how it works?
Shaping the Conversation: Predii Automotive AI Summit
Nazneen joined the Predii Automotive AI Summit alongside the CTOs of Ericsson and Cognizant to speak about what it takes to own your AI strategy in 2025. She shared lessons from red-teaming frontier models, including how Collinear’s AI Judges uncover failure modes that traditional evaluations miss, especially in regulated domains and high-stakes deployments. The conversation also touched on the critical role of data curation in improving real-world performance.
Big thanks to our friends at Predii and Cooley for hosting us!

Join Our Growing Team
We're expanding our team! Current openings:
Machine Learning Engineers
Senior Backend Engineer
View all open positions on our Careers page.
What's Next?
Ready to improve your AI's performance? Let's talk about how Collinear can help your team take your AI solution to production.