
Is your RL environment fair to your agent?
or ensuring that your hillclimbing budget is spent right :)


tldr; based on my current understanding of evaluations, RL environments, and the hill-climbing loop:
an environment (or evaluation) is fair when score differences are driven mainly by the capability you intend to measure, and are mostly invariant to nuisance factors like contamination, verifier bugs, environment drift, and benign prompt paraphrases.
I use the word evaluation and environment interchangeably since for all practical purposes of a modern multi-tool multi-step setup they are the same.
I hated taking exams in most of my courses in undergrad and then in my PhD. For the most part, I thought the exams did not measure the core skills required to apply the subject matter in the real world. I am afraid that the gradients for language models and agents share my feeling.
This article is an effort to distill the key features of a fair evaluation, scoped to RLVR and agent harnesses. Fair not with respect to a protected attribute like race or gender, but fair to the agent you are evaluating.
Two concrete things are in scope of this article, and more will soon follow:
The verifier inside an RLVR loop the function that takes a rollout as an input and produces a reward.
The agent harness: the tools, scaffolding, and protocol the agent acts through during rollouts, evals, and production.
What “fair to the agent” means
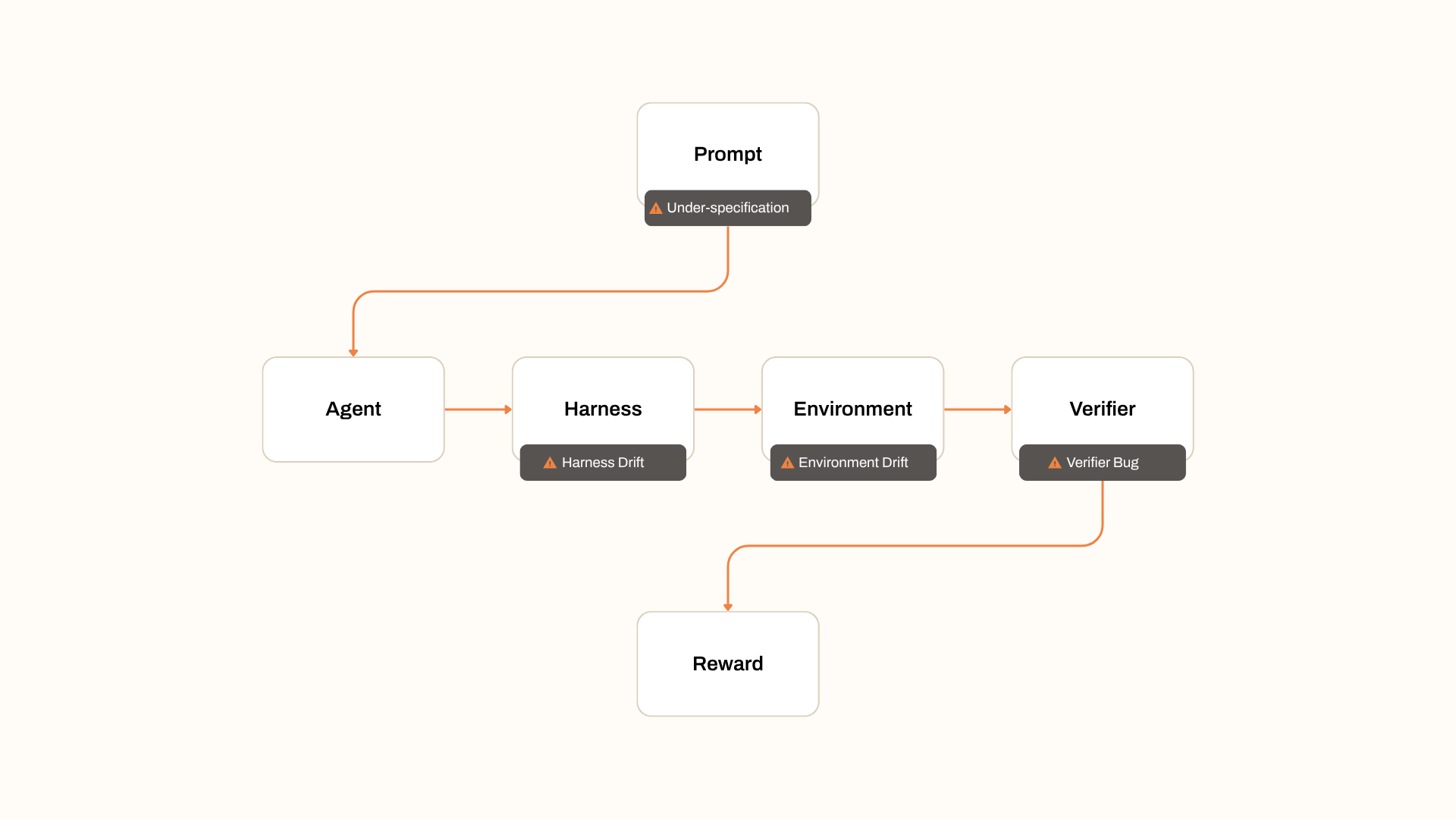
A capability is a repeatable ability of an agent to produce a desired outcome under specified conditions.
A fair eval is a measurement of a specific capability of the AI agent.
What is it not? It is not a measurement of outcomes which were not expected in the specified conditions.
Score differences between agents, or between training checkpoints should be explained by the capability under test. They should not be explained by nuisance factors:
Train-set contamination.
Verifier bugs and overfit rubrics.
Environment drift between runs.
Benign paraphrases of the prompt.
Harness details the agent never sees in deployment.
If an eval is sensitive to these, its not a fair eval.
Some ways an eval can be unfair
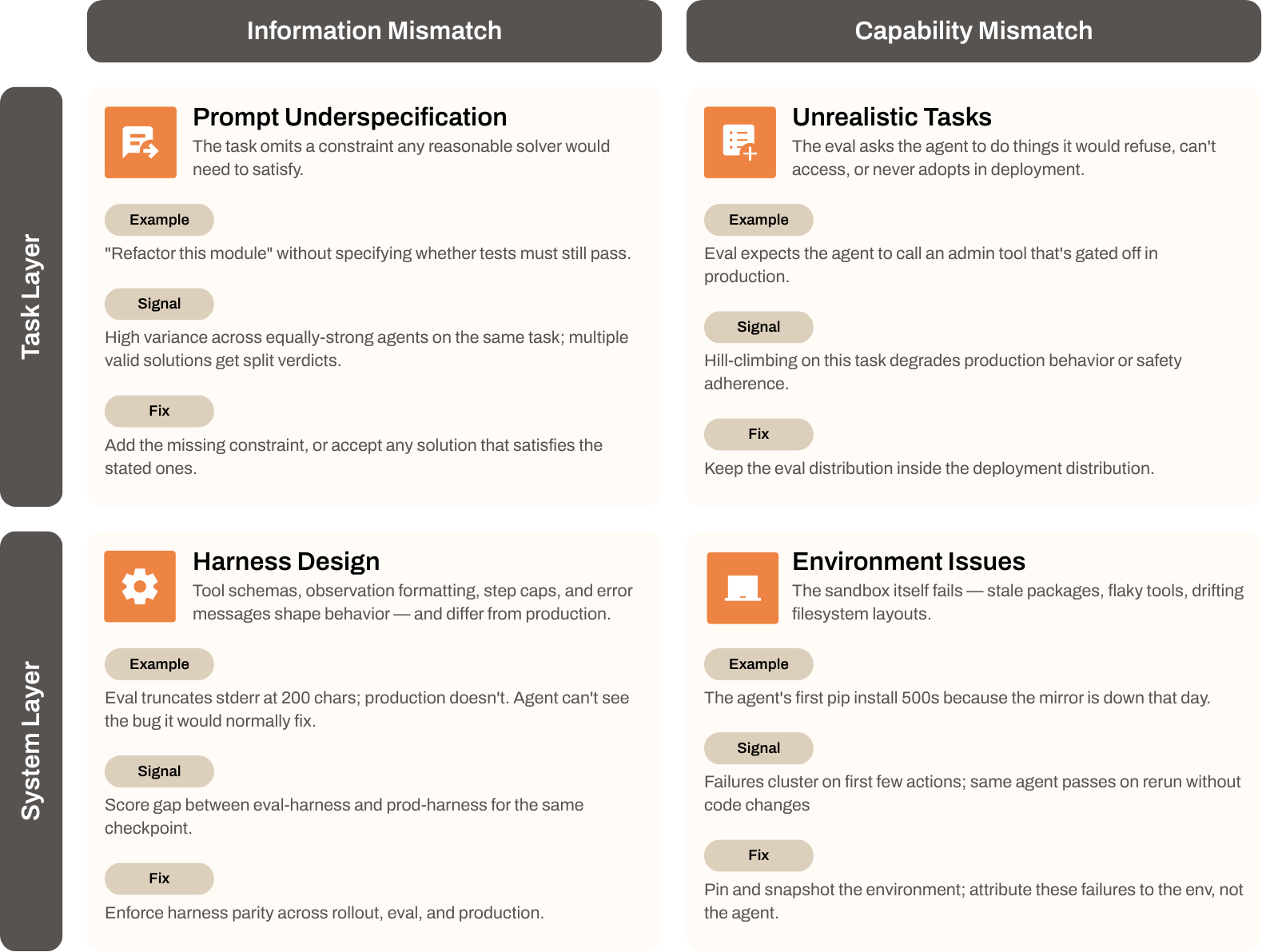
We discuss four most-popular ways here, but this is non-exhaustive, and I will keep extending this as we find more gaps.
1. Prompt Underspecification
This happens if the task misses a constraint any reasonable solver would need to achieve the task meaningfully.
If the verifier reports a fail, the outcome is confounded with ambiguity of the instructions. Two equally strong agents can swing several points apart on the same task. If the instructions are ambiguous the agent should be rewarded equally for equally valid solution paths.
2. Environment Issues
The sandbox has a stale package, a non-responsive tool, or a filesystem layout that drifts between runs or setups. The agent’s first action fails for reasons it cannot inspect. Such a failure should be attributed to the environment.
3. The harness design should be environment-centric
The agent interacts with the environment through the harness. Tool schemas, observation formatting, retry policy, max steps, error messages, all shape behavior.
Two harnesses with the “same” tools can produce very different scores. For example:
A truncated stderr hides the bug.
A misspecified tool schema can cause unnecessary confusion.
An unintentional 10-step cap might hamper a good agent’s planning capability.
Therefore any fair eval should have a uniform eval across different
4. Don’t ask it to do things it would not do in the real world
Your environment, tasks and verifiers should not expect the agent to achieve a goal which is unrealistic in practice. A few common ones:
Tasks the agent is told to refuse in production but expected to attempt in eval.
Tools available in the gym that do not exist in the deployed surface.
A persona or role the deployed system never adopts.
Since if the agent were to hillclimb for these - it would not improve the capability you want to measure.
The role the verifier plays
The verifier is a model of “what success looks like.”
A strict verifier on an underspecified prompt punishes reasonable behavior. A lenient verifier can turn failures into passes. Verifiers are rarely audited as carefully as the agents they grade but their errors compound at every step of hill-climbing.
Treat the verifier as a system under test.
Measure its agreement with humans.
Measure its variance across paraphrases of the same correct answer.
Measure its false-positive and false-negative rates.
Reward hacking is a fairness problem
In RL, the verifier is the reward. Anything the verifier accepts is a valid policy.
If the verifier can be satisfied without solving the task meaningfully, the agent will eventually find that shortcut. This is not the model’s or the algorithm’s fault. It is the eval’s fault. A few common shortcuts:
Producing answers in a format the verifier scores leniently.
Exploiting tool calls in a way that gets a good reward but doesn’t affect the state of the environment.
Pattern-matching the rubric’s expectation instead of producing a correct answer.
Outputting both the answer and its negation when the verifier checks for substring presence.
Fair RL requires that the only cheap way to get reward is to do the task. If a cheaper path exists, the agent harness improvement loop or the gradient across the rollouts will discover it, and rightly so.
A checklist for fair evaluations
Before you let an eval drive decisions or training:
Specification. Could a competent intelligent entity solve the task from the prompt alone, without insider knowledge?
Harness parity. Does the eval harness match the deployment harness on tools, formats, and limits?
Distribution match. Are eval tasks ones the agent would actually face, and be permitted to attempt in production?
Verifier audit. Has the verifier been graded against humans or SoTA model trajectories? What is its False Positive & False Negative rate?
Paraphrase invariance. Does the score change when the prompt is rewritten without changing meaning?
Failure attribution. When the agent fails, can you tell whether it was the agent, the harness, the environment, or the verifier?
Open questions
How do you measure verifier quality when human labels are themselves noisy or expensive?
What is the right unit of “agent failure” in long-horizon tasks where many small slips compound?
Can verifiers be co-trained with agents without collapsing into a stationary state where both of them are poor?
How do you detect reward hacking inside an RLVR loop before it shows up as a deployment regression?
What is the minimum harness contract that should be held constant across rollout, eval, and production?
For tasks with no programmatic verifier, how do you keep model-graded RLVR from drifting into preference-style noise?
If you’re shipping agents and model and have faced similar problems with fair evaluations, we should chat. We have a lot of interesting private and public evaluations which cover terminal use, MCP and computer use environments. Our focus is ensuring high-quality data. And fair-evaluations are a core tenet as we scale the horizons our agents operate on.