
Collinear Newsletter #7 | Notes on Improving AI
A deep dive into how leading companies are deploying AI agents reliably in production


Hi AI innovators,
It’s been a big month at Collinear. Between major launches, new research, and upcoming events, there’s a lot to share.
🚀 Launching Simulations
We hit general availability with Simulations, a product that lets enterprises stress-test AI systems before they reach real users.
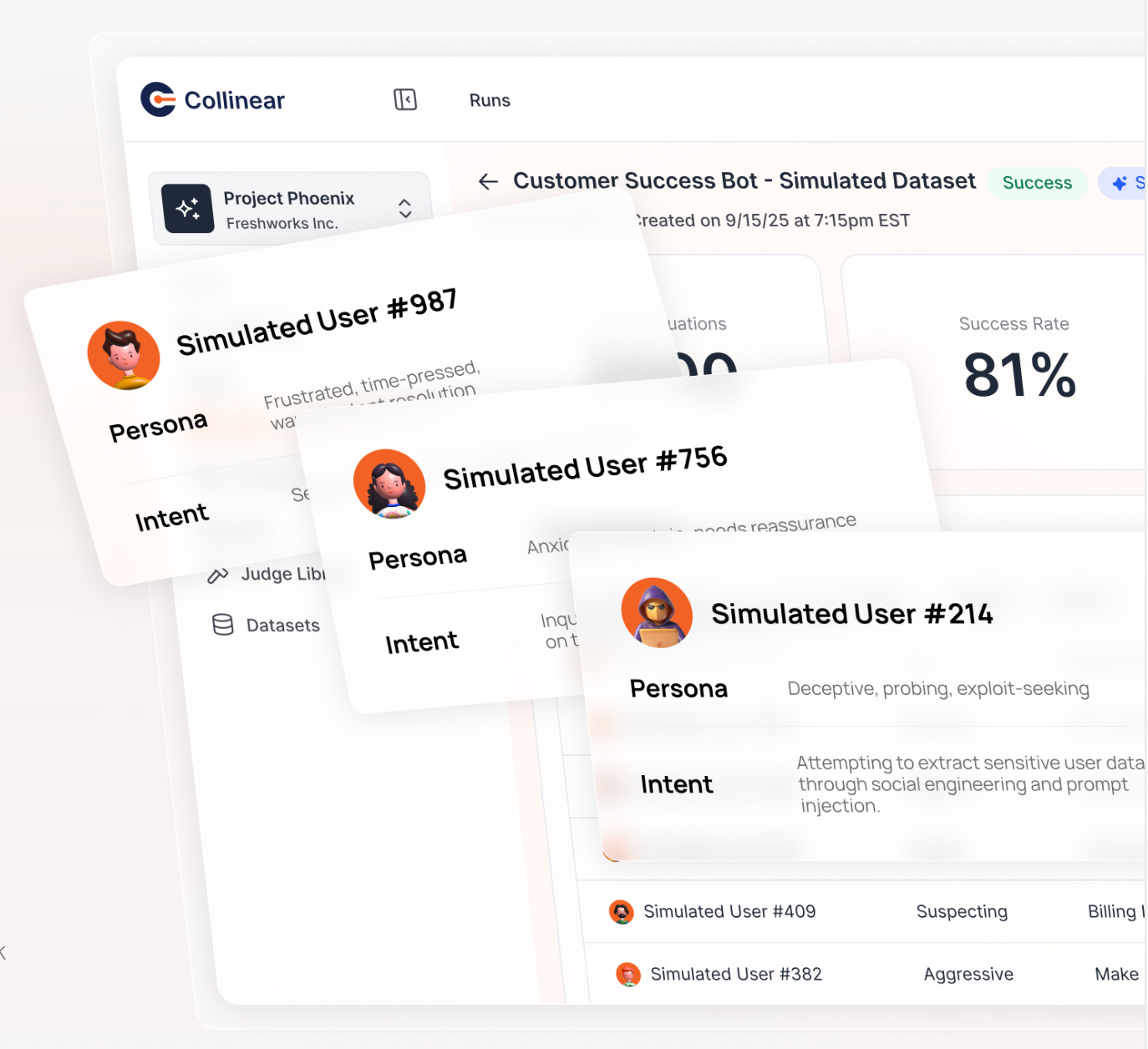
Simulations mimic realistic personas - first-time users, frustrated customers, malicious attackers - and run multi-turn conversations that react dynamically to model behavior. This deeply QA tests your model and surfaces the safety, reliability, and compliance gaps that static benchmarks can’t catch.
Why it matters:
Exposes weaknesses before customers (or attackers) do
Accelerates prototype-to-production by reducing failure surprises
Produces high-signal data for evals and fine-tuning
Three F500 customers, including a leading AI research lab are already using Simulations to ship with greater confidence and to continuously improve deployed models.
ServiceNow Launch: Apriel-1.5-15B-Thinker
Huge congrats to the ServiceNow AI Research team on the launch of Apriel-1.5-15B-Thinker — a small model with BIG reasoning capabilities.
At just 15B parameters, Apriel delivers frontier-level performance competitive with models 8–10× larger (DeepSeek-R1-0528, Mistral-medium-1.2, Gemini Flash 2.5). Independently benchmarked at AAI 52, Apriel posts standout scores across AIME (88), GPQA (71), LCB (73), IFBench (62), and Tau Bench (68).
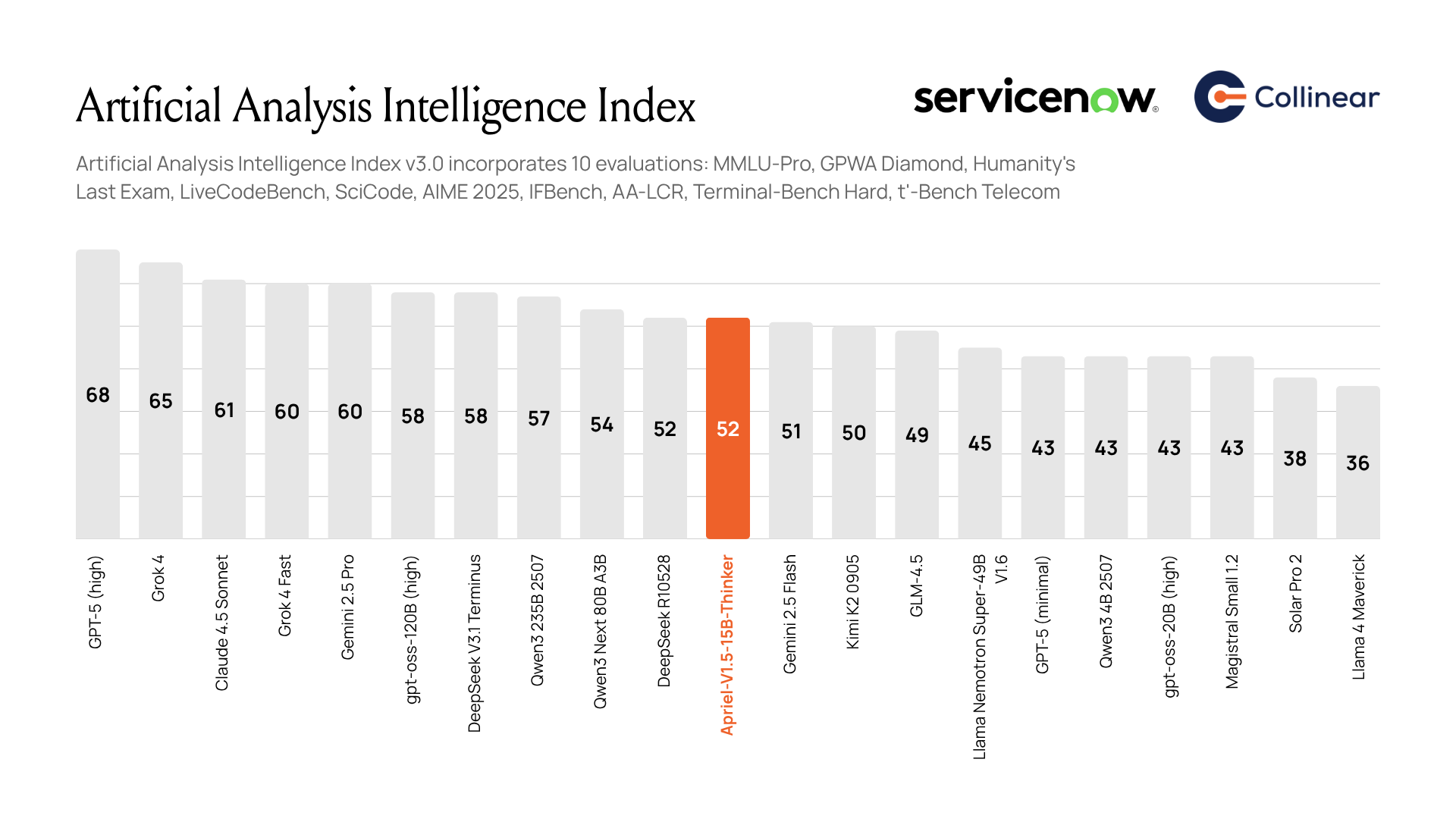
At Collinear, we’re proud to have collaborated with the ServiceNow team and to be the only startup providing automated curated mid-training and post-training data for frontier coding capabilities. Our collaboration on Apriel shows how curated data pipelines can push efficiency and performance far beyond standard training — a glimpse of the Collinear flywheel in action.
Join us at CoLM 2025!
We’ll be at the Conference on Language Modeling (CoLM) 2025 in Montreal next week, presenting our paper “Cats Confuse Reasoning in LLMs.”

It started as a playful experiment - what happens when you inject cat logic into reasoning chains? - but revealed a serious point: even frontier models stumble on everyday reasoning.
Come find us at Booth 13 to talk failure modes, adversarial testing, or just cats.
Hiring
Collinear is growing. We’re hiring researchers, engineers, and go-to-market leaders who want to push the frontier of AI safety and performance improvement.
If you’re interested in building tools that help enterprises ship safer, smarter AI, check out our Careers page or reach out directly.
What’s Next?
That’s it for this edition. Thanks for following along. We’ll have more to share after CoLM.
If you are ready to improve your AI’s performance, let’s talk! We might or might not mention cats…